高维协方差矩阵估计方法
1 概述
协方差矩阵估计是统计学和金融学中的核心课题之一,主要用于刻画多维随机变量之间的线性依赖关系。这一方法在风险管理、投资组合优化以及资产定价等领域具有广泛的应用价值。设\(p\)维随机向量\(\mathbf X=(X_1,\cdots,X_p)^T\),其协方差矩阵\(\Sigma\)是一个\(p\times p\)的对称矩阵,其第\((i,j)\)元素定义为: \[ \Sigma_{ij} = \text{Cov}(X_i, X_j) \] 其中\(\text{Cov}(X_i, X_j)\)表示\(X_i\)和\(X_j\)之间的协方差,而对角线元素\(\Sigma_{ii}\)则代表变量\(X_i\)的方差。
在Markowitz投资组合优化模型(又称均值-方差优化模型)中,协方差矩阵扮演着关键角色,用于量化资产之间的风险和相关关系。该模型通过在给定收益水平下最小化投资组合风险来构建有效前沿。假设\(\mathbf X\)表示\(p\)个风险资产的收益率,其预期收益和协方差矩阵分别为\(\boldsymbol \mu\)和\(\Sigma\)。记投资组合权重为\(\mathbf w\),则该优化问题可表述为: \[ \min_w w^T \Sigma w \quad \text{s.t.} \quad w^T \mu \ge \mu_p, \quad w^T \mathbf{1} = 1 \] 其中\(\mu_p\)为目标投资组合收益率,\(\mathbf{1}\)为全1向量。协方差矩阵的准确性直接影响资产间的风险分散效果,从而决定最优权重\(w\)的选择。通常,预期收益率向量\(\boldsymbol \mu\)和协方差矩阵\(\Sigma\)需要基于历史收益率数据进行估计。
假设我们观测到独立同分布样本\(\mathbf X_1, \mathbf X_2,\cdots,\mathbf X_n\),则样本协方差矩阵 \[ S = \frac{1}{n}\sum_{t=1}^n (\mathbf X_t-\bar{\mathbf X}) (\mathbf X_t-\bar{\mathbf X})^T \tag{1}\] 是协方差矩阵\(\Sigma\)的一个估计量,其中\(\bar{\mathbf X}=n^{-1}\sum_{t=1}^n \mathbf X_t\)为样本均值向量。在低维情形下(即\(n \gg p\)),样本协方差矩阵具有良好的性质:它可逆、一致,且具有渐近正态性,即\(\sqrt{n}(\text{vec}(S) - \text{vec}(\Sigma))\)依分布收敛于正态分布。此外,样本协方差矩阵\(S\)的特征值会收敛于总体协方差矩阵\(\Sigma\)的特征值。具体而言,若\(\lambda^*_1 \geq \lambda^*_2 \geq \dots \geq \lambda^*_p\)为\(\Sigma\)的特征值,\(\lambda_1 \geq \lambda_2 \geq \dots \geq \lambda_p\)为\(S\)的特征值,则有: \[ \lambda_i \overset{P}{\to} \lambda^*_i \quad \text{当} \quad n \to \infty. \] 然而,在高维情形下(即维度\(p\)与样本量\(n\)相当或更大,\(p \gg n\)),样本协方差矩阵的估计会面临一系列挑战,导致其失效。当\(p > n\)时,样本协方差矩阵\(S\)将变为奇异矩阵,且其估计偏差和方差显著增大。此外,样本协方差矩阵\(S\)的特征值与总体协方差矩阵\(\Sigma\)的特征值之间会出现显著偏差,样本特征值分布也会偏离真实分布。通常,总体协方差矩阵\(\Sigma\)的最大特征值会被高估,而最小特征值则会被低估。
# 高维情形下样本协方差矩阵失效的R代码示例
# 加载必要的库
library(MASS)
library(Matrix)
# 设置随机种子以确保结果可重复
set.seed(123)
# 参数设置
p <- 100 # 维度
n <- 50 # 样本量
# 生成真实协方差矩阵(假设为对角矩阵)
Sigma_true <- diag(p)
# 生成多元正态分布数据
X <- mvrnorm(n, mu = rep(0, p), Sigma = Sigma_true)
# 计算样本协方差矩阵
Sigma_sample <- cov(X)
# 检查样本协方差矩阵的奇异性
if (rankMatrix(Sigma_sample) < p) {
cat("样本协方差矩阵是奇异的(不可逆)。\n")
} else {
cat("样本协方差矩阵是非奇异的(可逆)。\n")
}样本协方差矩阵是奇异的(不可逆)。# 比较真实协方差矩阵和样本协方差矩阵的特征值
eigen_true <- eigen(Sigma_true)$values
eigen_sample <- eigen(Sigma_sample)$values
# 绘制特征值对比图
plot(eigen_true, type = "b", col = "blue", ylim = range(c(eigen_true, eigen_sample)),
xlab = "特征值索引", ylab = "特征值", main = "真实与样本协方差矩阵的特征值对比")
lines(eigen_sample, type = "b", col = "red")
legend("topright", legend = c("真实特征值", "样本特征值"), col = c("blue", "red"), lty = 1)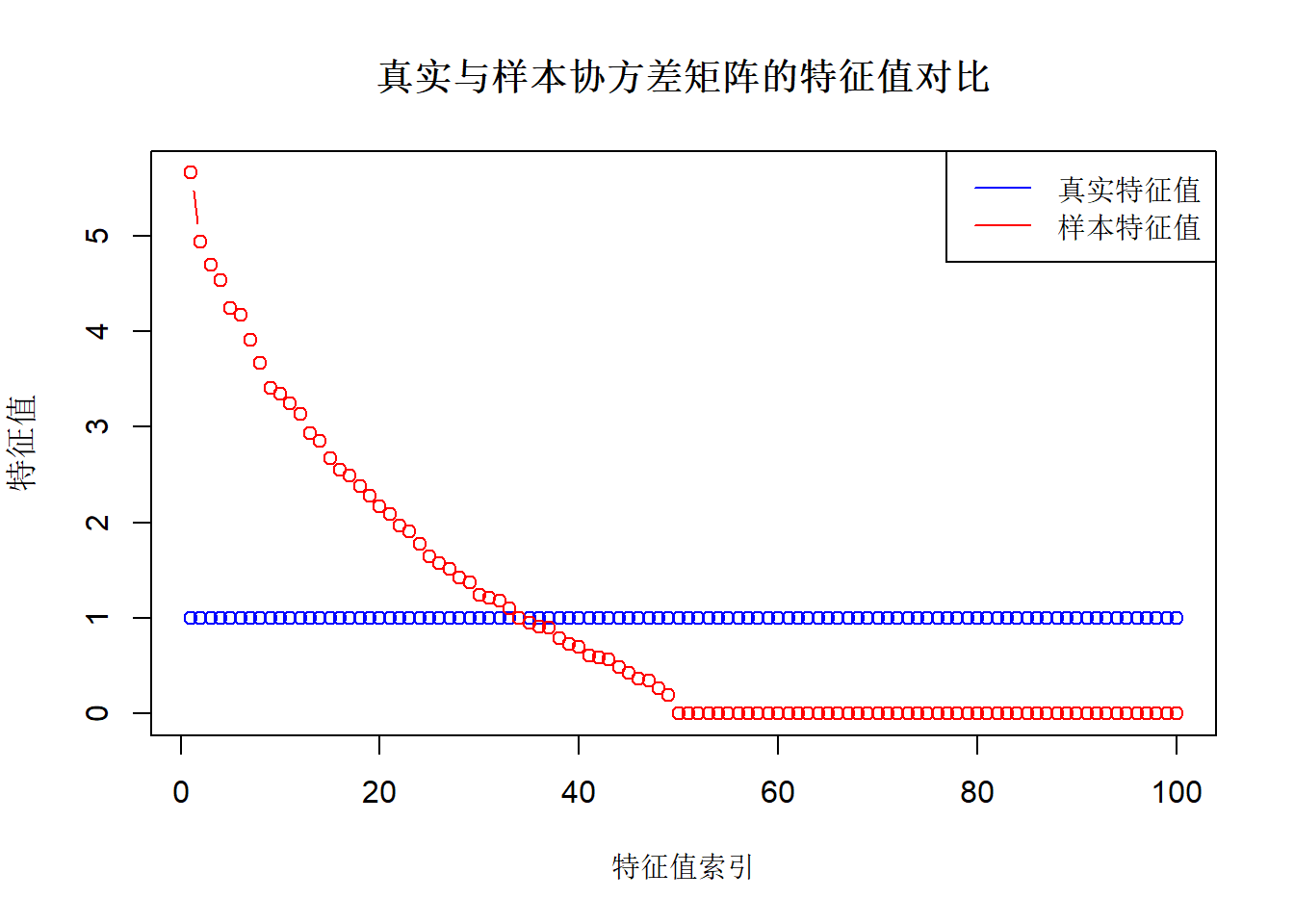
# 计算条件数
condition_number_true <- max(eigen_true) / min(eigen_true)
condition_number_sample <- abs(max(eigen_sample) / min(eigen_sample))
cat("真实协方差矩阵的条件数:", condition_number_true, "\n")真实协方差矩阵的条件数: 1 cat("样本协方差矩阵的条件数:", condition_number_sample, "\n")样本协方差矩阵的条件数: 3.810329e+15 # 检查样本协方差矩阵的条件数是否显著增大
if (condition_number_sample > 10 * condition_number_true) {
cat("样本协方差矩阵的条件数显著增大,表明估计不稳定。\n")
} else {
cat("样本协方差矩阵的条件数相对稳定。\n")
}样本协方差矩阵的条件数显著增大,表明估计不稳定。# 输出真实和样本协方差矩阵的前5行和前5列
cat("真实协方差矩阵(前5x5):\n")真实协方差矩阵(前5x5):print(Sigma_true[1:5, 1:5]) [,1] [,2] [,3] [,4] [,5]
[1,] 1 0 0 0 0
[2,] 0 1 0 0 0
[3,] 0 0 1 0 0
[4,] 0 0 0 1 0
[5,] 0 0 0 0 1cat("样本协方差矩阵(前5x5):\n")样本协方差矩阵(前5x5):print(Sigma_sample[1:5, 1:5]) [,1] [,2] [,3] [,4] [,5]
[1,] 1.525719367 0.007196938 -0.116373354 0.060185045 0.288532327
[2,] 0.007196938 0.969917411 -0.009698882 -0.001109417 0.174393596
[3,] -0.116373354 -0.009698882 1.179549189 -0.149925659 0.039293879
[4,] 0.060185045 -0.001109417 -0.149925659 0.613148899 0.001869769
[5,] 0.288532327 0.174393596 0.039293879 0.001869769 0.9249938582 高维协方差矩阵的稀疏结构假设与相关估计方法
估计高维协方差矩阵的第一种思路是假定协方差矩阵具有一定的稀疏结构,即假定协方差矩阵\(\Sigma\)中绝大多数元素为0,进而通过合适的方法对样本协方差矩阵\(S\)进行修正,得到最终的稀疏估计。现有稀疏结构假设大致可分为两类:带化(bandable)矩阵和稀疏矩阵,带化矩阵是一种特殊的稀疏矩阵。
2.1 带化矩阵假设下的估计方法
当\(\mathbf X\)中的变量存在自然的顺序,比如时间序列变量或者空间变量,那么可以很自然的假设协方差矩阵呈现局部依赖结构,即矩阵中的非对角元素绝对值随着该元素距离对角线距离的增加而减小,直至为0。这一类协方差矩阵成为带化矩阵,其特征是非0元素集中在对角线附近的带状区域里,区域外的元素全部为0。
2.1.1 Banding方法
Banding方法(Bickel and Levina 2008b)是一种用于估计带化高维协方差矩阵的方法,该方法保留样本协方差矩阵主对角线及其附近的元素,将远离主对角线的元素置为零,从而在高维数据环境下获得更稳健的带化稀疏估计。具体来说,带化后的协方差矩阵\(\hat{\Sigma}^{\text{band}}\)定义为: \[ \hat{\Sigma}_{ij}^{\text{band}} = S_{ij} \cdot I\left( |i - j| \leq k \right) \tag{2}\] 其中,\(I(\cdot)\)是示性函数,\(k\)是带宽参数,控制保留的元素范围,一般需要根据经验或者依赖交叉验证进行选择。在局部依赖假设下,Banding方法能够一致地估计真实协方差矩阵,在适当的带宽选择下,Banding方法的估计误差以较快的速度收敛到零。
2.1.2 Tapering方法
Tapering(渐缩,Cai, Zhang and Zhou 2010)方法是另一种用于带化高维协方差矩阵估计的方法。该方法在保留主对角线及其附近的元素的同时对元素进行平滑衰减,从而获得更稳健的估计。Tapering估计量的表达式为 \[ \hat{\Sigma}_{ij}^{\text{taper}} = \frac{2S_{ij}}{k}\left\{(k-|i-j|)_+-(k/2-|i-j|)_+ \right\} \tag{3}\] 其中\((x)_+=\max(x,0)\),\(k\)同样为带宽参数。 式 3 可以等价地表述为 \[ \hat{\Sigma}_{ij}^{\text{taper}} = \begin{cases} S_{ij} \quad &\text{if} \quad |i-j|\le k/2 \\ 2(1-|i-j|/k)S_{ij} \quad &\text{if} \quad k/2 < |i-j| \le k \\ 0 \quad &\text{if} \quad |i-j|>k. \end{cases} \] 与 式 2 做对比,tapering方法对\(k/2 < |i-j| \le k\)区域内的元素做了平滑衰减处理,其权重由1逐步降低至0,而banding方法对该区域的元素的权重依然保持为1,继而在\(k\)处骤降至0。在一定的假设条件下,tapering方法比banding方法具有更快的收敛速率。
if (!requireNamespace("cvCovEst", quietly = TRUE)) {
install.packages("cvCovEst")
}
library(cvCovEst)
library(MASS)
library(Matrix)
# 设置随机种子以确保结果可重复
set.seed(123)
# 参数设置
p <- 100 # 维度
n <- 50 # 样本量
band_width <- 0.05 # 带化处理的阈值
# 生成空间距离矩阵(假设为1D空间上的点)
locations <- seq(0, 1, length.out = p) # 在[0, 1]区间上均匀分布的点
dist_matrix <- as.matrix(dist(locations, method = "euclidean"))
# 生成协方差矩阵(协方差随距离减小,超过阈值后为0)
Sigma_true <- exp(-dist_matrix / 0.02) # 协方差随距离指数衰减
Sigma_true[dist_matrix > band_width] <- 0 # 带化处理
diag(Sigma_true) <- 1 # 对角线元素为1
# 生成多元正态分布数据
X <- mvrnorm(n, mu = rep(0, p), Sigma = Sigma_true)
# 使用cvCovEst包进行协方差矩阵估计,并使用交叉验证选择带宽
cv_banding <- cvCovEst(
dat = X,
estimators = c(bandingEst),
estimator_params = list(bandingEst = list(k = seq(1L, 10L, 1L))),
cv_scheme = "v_fold",
v_folds = 5
)
cv_tapering <- cvCovEst(
dat = X,
estimators = c(taperingEst),
estimator_params = list(
taperingEst = list(k = seq(2L, 20L, 2L))
),
cv_scheme = "v_fold",
v_folds = 5
)
# 输出估计的协方差矩阵
Sigma_banding <- cv_banding$estimate
Sigma_tapering <- cv_tapering$estimate
# 输出估计所选择的带宽
cat("banding方法的带宽:", cv_banding$estimator)banding方法的带宽: bandingEst, k = 3cat("tapering方法的带宽:", cv_tapering$estimator)tapering方法的带宽: taperingEst, k = 4cat("banding估计的协方差矩阵(前5x5):\n")banding估计的协方差矩阵(前5x5):print(Sigma_banding[1:5, 1:5]) [,1] [,2] [,3] [,4] [,5]
[1,] 0.93750898 0.6236684 0.3547426 -0.01915142 0.0000000
[2,] 0.62366837 1.0784256 0.5959016 0.26162694 0.1375792
[3,] 0.35474256 0.5959016 0.7676698 0.39133696 0.3005238
[4,] -0.01915142 0.2616269 0.3913370 0.75291543 0.4742981
[5,] 0.00000000 0.1375792 0.3005238 0.47429814 1.0099289cat("tapering估计的协方差矩阵(前5x5):\n")tapering估计的协方差矩阵(前5x5):print(Sigma_tapering[1:5, 1:5]) [,1] [,2] [,3] [,4] [,5]
[1,] 0.93750898 0.62366837 0.3547426 -0.00957571 0.00000000
[2,] 0.62366837 1.07842562 0.5959016 0.26162694 0.06878958
[3,] 0.35474256 0.59590156 0.7676698 0.39133696 0.30052384
[4,] -0.00957571 0.26162694 0.3913370 0.75291543 0.47429814
[5,] 0.00000000 0.06878958 0.3005238 0.47429814 1.00992891# 比较估计矩阵和真实矩阵的Frobenius范数误差
error <- c(norm(Sigma_banding - Sigma_true, type = "F"),
norm(Sigma_tapering - Sigma_true, type = "F"))
cat("banding和tapering方法估计矩阵与真实矩阵的Frobenius范数误差分别为:", error, "\n")banding和tapering方法估计矩阵与真实矩阵的Frobenius范数误差分别为: 4.488601 4.499928 # 可视化真实协方差矩阵和估计协方差矩阵
library(ggplot2)
library(reshape2)
# 真实协方差矩阵可视化
Sigma_true_melted <- melt(Sigma_true)
ggplot(Sigma_true_melted, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 0) +
labs(title = "True Covariance Matrix", x = "Variable", y = "Variable") +
theme_minimal()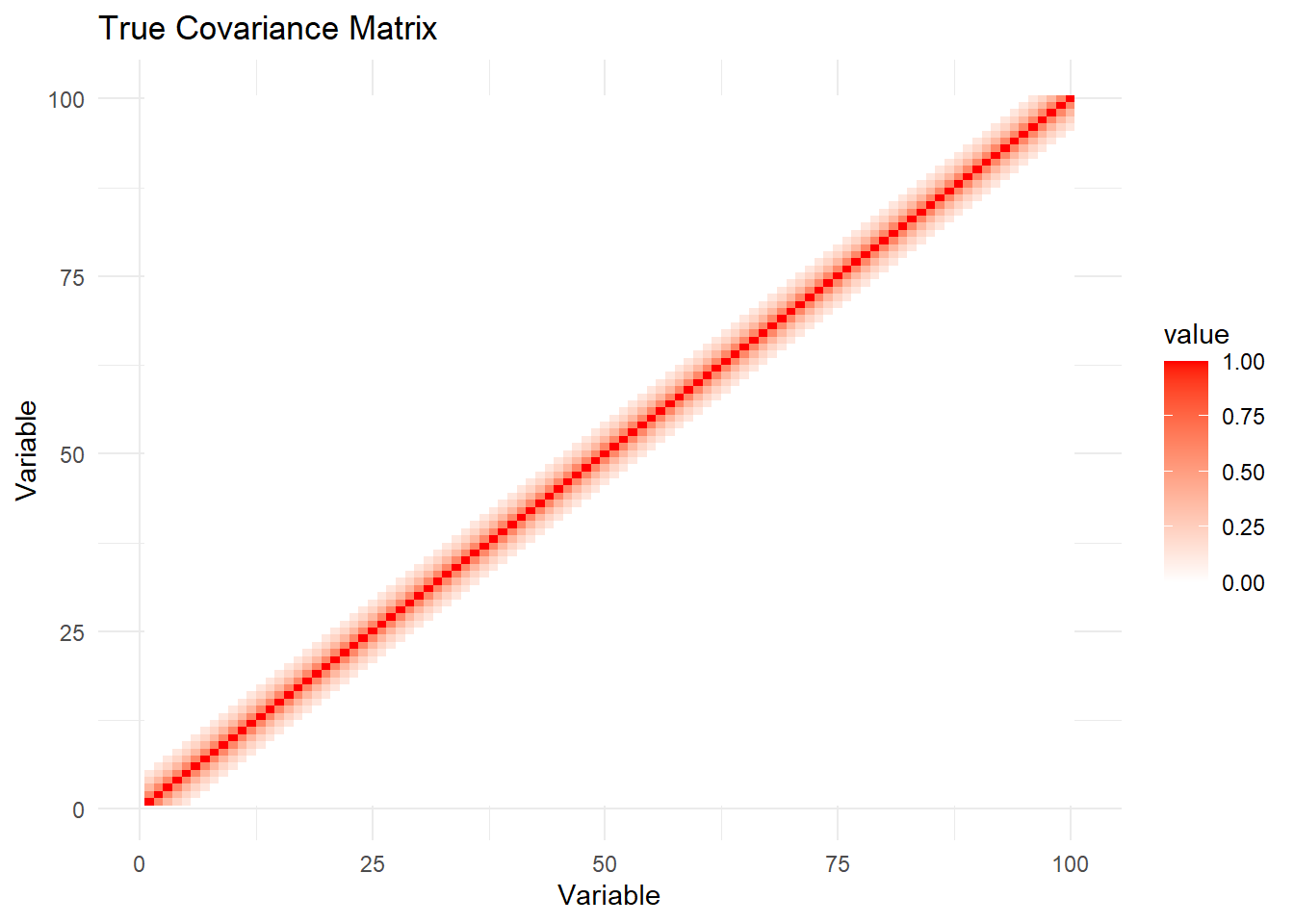
# banding估计协方差矩阵可视化
Sigma_banding_melted <- melt(Sigma_banding)
ggplot(Sigma_banding_melted, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 0) +
labs(title = "Banding Estimated Covariance Matrix", x = "Variable", y = "Variable") +
theme_minimal()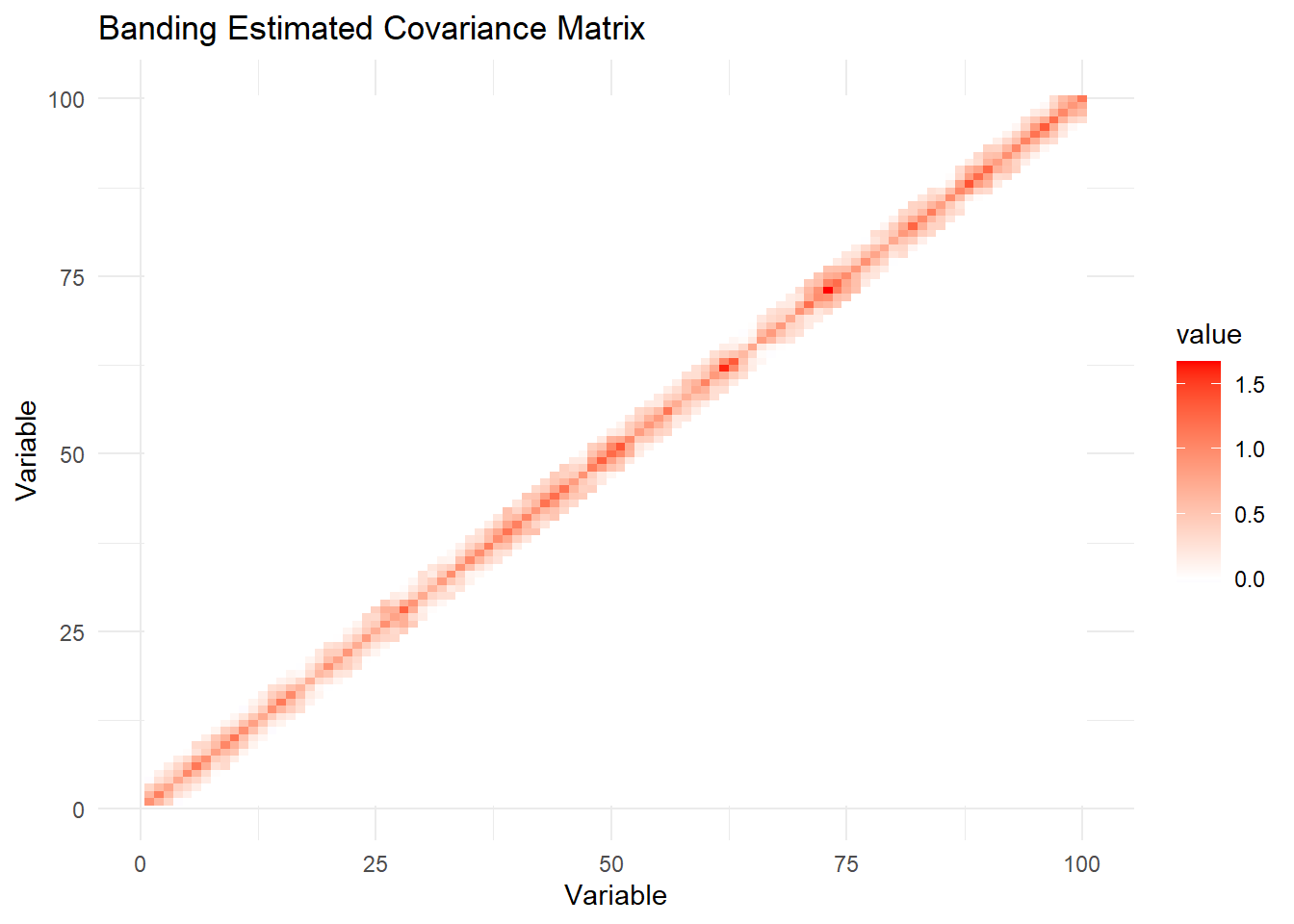
# tapering估计协方差矩阵可视化
Sigma_tapering_melted <- melt(Sigma_tapering)
ggplot(Sigma_tapering_melted, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 0) +
labs(title = "Tapering Estimated Covariance Matrix", x = "Variable", y = "Variable") +
theme_minimal()
2.2 稀疏性假设下的阈值估计方法及其拓展
2.2.1 Hard Thresholding(硬阈值法)
硬阈值法(Bickel and Levena 2008a)是一种基于稀疏性假设的高维协方差矩阵估计方法,该方法对样本协方差矩阵\(S\)的非对角线元素\(S_{ij}\)进行硬阈值处理,保留绝对值大于阈值\(\omega\)的元素,将小于等于\(\omega\)的元素置为零: \[ \hat{\Sigma}_{ij}^{\text{hard-thresh}} = \begin{cases} S_{ij} \quad &\text{if}\quad i=j \\ S_{ij}\cdot I\left( |S_{ij}| > \omega \right) \quad &\text{if}\quad i\ne j \end{cases} \tag{4}\] 其中\(\omega>0\)为预先给定的阈值水平。当随机向量\(\mathbf X\)为Gaussian或者sub-Gaussian时,理论上阈值可以设定为\(\omega = C\sqrt{\frac{\log p}{n}}\),其中\(C>0\),但是该方式仍然包含未知的常数\(C\),实际中阈值选择通常基于交叉验证确定。硬阈值法方法易于理解和实现,计算效率高,能够有效利用高维数据的稀疏性,减少噪声。在一定的假设条件下,硬阈值法具有一致性。
2.2.2 Soft Thresholding(软阈值法)
软阈值法在硬阈值的基础上融入了压缩估计,它的核心思想是通过将小于阈值的元素向零截断,同时减少大于阈值的元素的绝对值,从而实现数据的平滑稀疏化。其表达式为 \[ \hat{\Sigma}_{ij}^{\text{soft-thresh}} = \begin{cases} S_{ij} \quad &\text{if}\quad i=j \\ \mathrm{sign}(S_{ij})(|S_{ij}|- \omega)_+ \quad &\text{if}\quad i\ne j \end{cases} \tag{5}\] 其中\(\omega>0\)为阈值参数。具体而言,当样本协方差矩阵非对角线元素\(|S_{ij}|<\omega\)时将其设置为0,当\(S_{ij}>\omega\)时将其向0进行线性压缩\(S_{ij}-\omega\),当\(S_{ij}<-\omega\)时将其向0调整为\(S_{ij}+\omega\)。
2.2.3 Generalized Thresholding(广义阈值法)
广义阈值法是硬阈值法和软阈值法的进一步拓展,该方法使用一般化的压缩函数\(h(\cdot;\omega)\)作用于样本协方差矩阵的非对角线元素: \[ \hat{\Sigma}_{ij}^{\text{thresh}} = \begin{cases} S_{ij} \quad &\text{if}\quad i=j \\ h(S_{ij};\omega) \quad &\text{if}\quad i\ne j \end{cases} \tag{6}\] 其中\(\omega\)为阈值参数。压缩函数\(h(\cdot;\omega)\)须满足3个条件: (1). \(h(z;\omega)=0\)当\(|z|\le \omega\); (2). \(|h(z;\omega)|\le |z|\); (3). \(|h(z;\omega)-z|\le \omega\)。 第1个条件是阈值效应,即将绝对值小于\(\omega\)的值截断为0,第2个条件是压缩效应,第3个条件规定了压缩的程度。
硬阈值法和软阈值法作为广义阈值法的特例,它们对应的压缩函数分别为 \[ h^{\text{hard-thresh}}(z;\omega)=z\cdot I(|z|>\omega), \] 以及 \[ h^{\text{soft-thresh}}(z;\omega)=\mathrm{sign}(z)(|z|-\omega)_+. \] 另外两种常用的压缩函数分别是SCAD(Smoothly Clipped Absolute Deviation): \[ h^{\text{SCAD}}(z;\omega)=\begin{cases} \mathrm{sign}(z)(|z|-\omega)_+ \quad &|z|\le 2\omega \\ \{(a-1)z-\mathrm{sign}(z)a\omega\}/(a-2) \quad & 2\omega <|z|\le a\omega\\ z \quad &|z|>a\omega \end{cases} \] 其中\(a>2\)为形状参数,一般取值3.7,以及MCP(minimax concave penalty): \[ h^{\text{MCP}}(z;\omega) = \begin{cases} (a/(a-1))\mathrm{sign}(z)(|z|-\omega)_+ \quad & |z|\le a\omega\\ z \quad & |z|>a\omega \end{cases} \] 其中形状参数\(a>1\)一般取值为3。
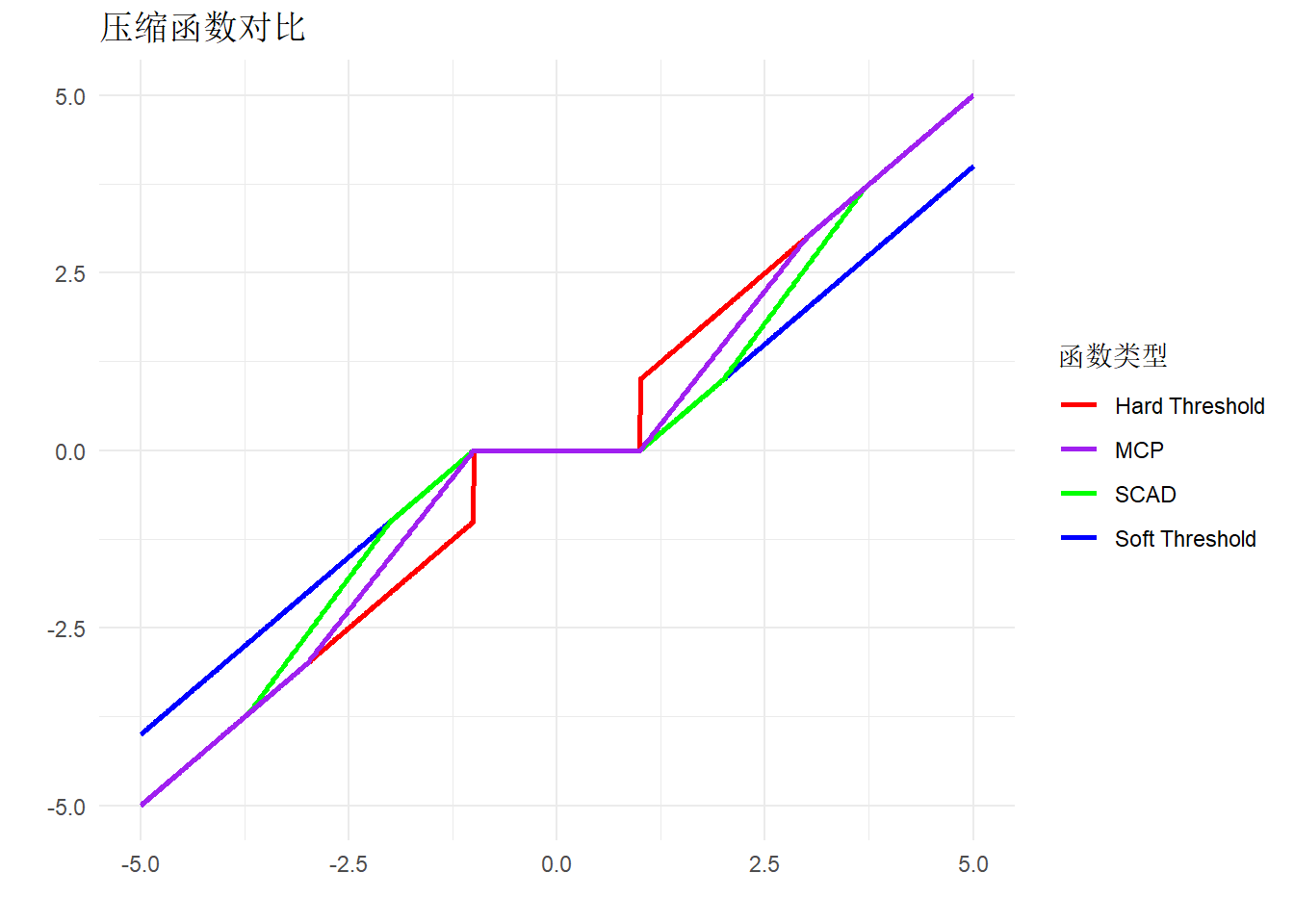
上图绘制了硬阈值、软阈值、SCAD和MCP四种压缩函数在阈值\(\omega=1\)时的图像。首先,硬阈值压缩函数是不连续的,在阈值处直接将\(|z|\)截断为0;第二,由于在阈值之外的区域引入了线性压缩,软阈值压缩函数连续,但是同时在\(|z|\)较大的区域引入了偏差,而绝对值较大区域往往是不需要进行额外压缩估计的;第三,SCAD和MCP在保留了软阈值的连续性的同时,避免了在绝对值较大区域进行压缩估计从而出现偏差。
2.2.4 广义阈值法的等价惩罚回归表示
广义阈值法 式 6 可以等价地表示为以下惩罚最小二乘回归的解: \[ \hat{\Sigma}^{\text{thresh}} = \arg\min_{\Sigma} \left\{ \frac{1}{2} \|S - \Sigma\|_F^2 + \sum_{i \neq j} p(|\Sigma_{ij}|;\omega) \right\} \tag{7}\] 其中,\(S\)为样本协方差矩阵,\(p(\cdot;\omega)\)为惩罚函数,需要指出的是,我们只对非对角线元素施加惩罚,\(\|\cdot\|_F\)表示Frobenius范数,一个\(p\times p\)维矩阵\(A\)的Frobenius范数表示为\(\|A\|_F=\sqrt{\sum_{i=1}^p\sum_{j=1}^p A_{ij}^2}\)。
Antoniadis and Fan (2001) 仔细讨论了广义阈值法中的压缩函数与惩罚最小二乘回归中的惩罚函数一一对应关系,总的来说,压缩函数是惩罚函数的的次梯度。 表 1 分别列出了硬阈值、软阈值、SCAD以及MCP四种方法对应的压缩函数和惩罚函数。需要指出的是,软阈值方法对应的正好是Lasso惩罚函数。
| 方法 | 压缩函数 | 惩罚函数 |
|---|---|---|
| 硬阈值 | \(h(z;\omega) = z \cdot I(|z| > \omega)\) | \(p(z;\omega) = \omega^2 - \frac{(|z| - \omega)^2}{2} \cdot I(|z| < \omega)\) |
| 软阈值 | \(h(z;\omega) = \text{sign}(z) \cdot (|z| - \omega)_+\) | \(p(z;\omega) = \omega |z|\) |
| SCAD | \(h(z;\omega) = \begin{cases} \text{sign}(z) \cdot (|z| - \omega)_+ & \text{if } |z| \leq 2\omega, \\\ \frac{(a-1)z - \text{sign}(z) \cdot a \omega}{a-2} & \text{if } 2\omega < |z| \leq a\omega, \\ z & \text{if } |z| > a\omega \end{cases}\) | \(p(z;\omega) = \begin{cases} \omega |z| & \text{if } |z| \leq \omega, \\ \frac{2a\omega |z| - z^2 - \omega^2}{2(a-1)} & \text{if } \omega < |z| \leq a\omega, \\ \frac{(a+1)\omega^2}{2} & \text{if } |z| > a\omega \end{cases}\) |
| MCP | \(h(z;\omega) = \begin{cases} \text{sign}(z) \cdot (|z| - \omega)_+ & \text{if } |z| \leq a\omega, \\ \frac{a}{a-1} \cdot z & \text{if } |z| > a\omega \end{cases}\) | \(p(z;\omega) = \begin{cases} \omega |z| - \frac{z^2}{2a} & \text{if } |z| \leq a\omega, \\ \frac{a \omega^2}{2} & \text{if } |z| > a\omega \end{cases}\) |
惩罚最小二乘回归不仅提供了广义阈值法的另外一种解释,还为高维协方差矩阵的稀疏估计提供了更为丰富的处理方式。一般来说,经阈值处理后的协方差矩阵估计量在大样本下是满足正定性的,但是在有限样本下正定性可能不成立。为了始终保证估计量正定、可逆,Liu et al (2014)在 式 7 中融入了正定性限制条件: \[ \hat{\Sigma}^{\text{EC2}} = \arg\min_{\lambda_{min}(\Sigma)\ge \tau} \left\{ \frac{1}{2} \|S - \Sigma\|_F^2 + \sum_{i \neq j} p(|\Sigma_{ij}|;\omega) \right\}, \] 其中约束条件\(\lambda_{min}(\Sigma)\ge \tau\),即矩阵估计量的最小特征值存在下界\(\tau>0\),保证了所得到的协方差矩阵估计既满足稀疏性又符合正定要求。这一估计量称为EC2(estimation of covariance with eigenvalue constraints)估计量。
2.2.5 阈值法的自适应改进
上述阈值方法的一个不足之处在于其没有将\(\mathbf X\)边际分布可能存在的方差异质性纳入考虑,导致阈值处理在不同变量间存在尺度差异,或者说对于不同变量间的样本协方差施加的惩罚力度存在差异。基于这一不足,Cai and Liu (2011)在硬阈值法的基础上提出了Adaptive Thresholding(自适应阈值法): \[ \hat{\Sigma}_{ij}^{\text{ada-thresh}} = \begin{cases} S_{ij} \quad &\text{if}\quad i=j \\ S_{ij}\cdot I\left( |S_{ij}|/SE(S_{ij}) > \omega \right) \quad &\text{if}\quad i\ne j \end{cases} \] 其中\(SE(S_{ij})\)是协方差估计量\(S_{ij}\)的标准误。这一估计量能够自适应数据的不同尾部分布特征,还能够容许数据中可能存在厚尾分布。
Adaptive Lasso(自适应Lasso)是一种基于软阈值方法的自适应改进,由Rothman, Levina and Zhu (2009)提出。软阈值法对应 式 7 中的LASSO惩罚,Adaptive Lasso在Lasso惩罚函数的基础上引入自适应权重\(\tau_{ij}\),对不同的协方差矩阵元素进行不同程度的惩罚: \[ \hat{\Sigma}^{\text{ada-lasso}} = \arg\min_{\Sigma} \left\{ \frac{1}{2} \|S - \Sigma\|_F^2 + \sum_{i \neq j} \omega \tau_{ij} |\Sigma_{ij}| \right\} \] 其中权重通常基于初始估计(如样本协方差矩阵)计算,比如 \[ \tau_{ij} = \frac{1}{|S_{ij}|^\gamma} \] 其中,\(\gamma > 0\)是控制权重衰减速度的参数。
# 安装并加载必要的包
library(cvCovEst)
library(Matrix)
# 设置随机种子
set.seed(123)
# 生成一般性的稀疏高维协方差矩阵
n <- 50 # 样本量
p <- 100 # 变量维度
# 随机生成二维地理坐标
set.seed(123)
coords <- matrix(runif(p * 2, 0, 10), nrow = p, ncol = 2) # 生成 p 个点的坐标
# 计算距离矩阵
dist_matrix <- as.matrix(dist(coords))
# 基于距离生成稀疏协方差矩阵
threshold <- 2 # 距离阈值
true_cov <- exp(-dist_matrix) # 使用指数核函数生成协方差
true_cov[dist_matrix > threshold] <- 0 # 距离超过阈值的设为 0
diag(true_cov) <- 1 # 对角线设为 1
# 生成多元正态分布数据
X <- MASS::mvrnorm(n, mu = rep(0, p), Sigma = true_cov)
# 使用 cvCovEst 包进行协方差矩阵估计
# 将硬阈值、SCAD 和自适应 Lasso 作为列表传入
result <- cvCovEst(
dat = X,
estimators = c(
thresholdingEst,
scadEst,
adaptiveLassoEst
),
estimator_params = list(
thresholdingEst = list(gamma = seq(0.3, 0.6, length.out = 20)),
scadEst = list(lambda = seq(0.1, 0.4, length.out = 20)),
adaptiveLassoEst = list(lambda = seq(0.1, 0.4, length.out = 20), n = 0.9)
),
cv_scheme = "v_fold",
cv_loss = cvMatrixFrobeniusLoss
)
# 比较三种方法
cv_sum <- summary(result, dat_orig = X)
# 三种方法对应的最优超参数
cv_sum$bestInClass# A tibble: 3 × 6
estimator hyperparameter cv_risk cond_…¹ sign spars…²
<chr> <chr> <dbl> <dbl> <chr> <dbl>
1 scadEst lambda = 0.210526315789474 2511. -144 IND 0.82
2 adaptiveLassoEst lambda = 0.273684210526316, n … 2512. -183 IND 0.9
3 thresholdingEst gamma = 0.457894736842105 2520. -13.4 IND 0.97
# … with abbreviated variable names ¹cond_num, ²sparsity# 三种方法的热度图
plot(result, dat_orig = X, estimator = c('thresholdingEst', 'scadEst', 'adaptiveLassoEst'),
plot_type = "heatmap", stat = c('min'), abs_v = F)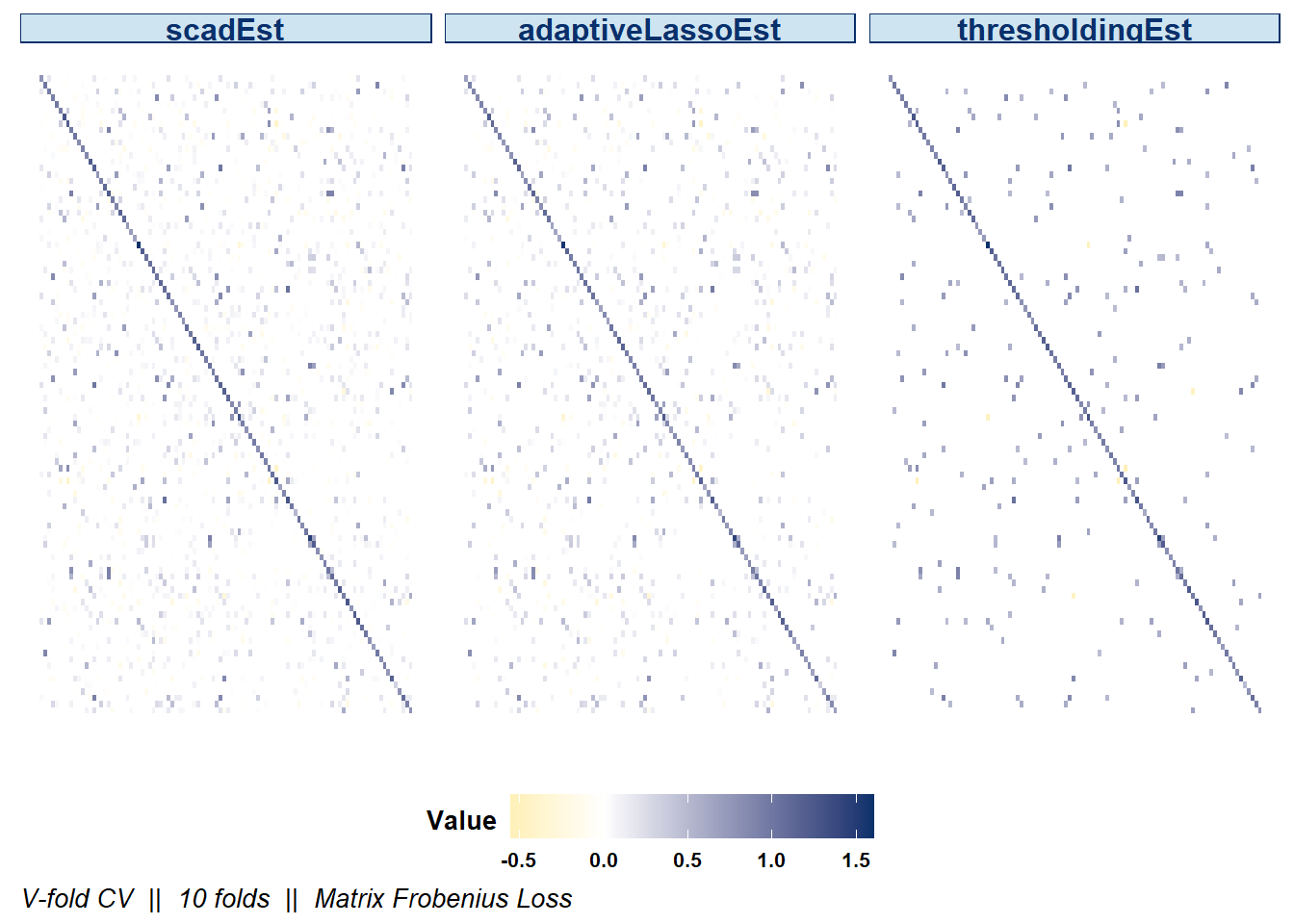
# 提取最佳估计结果
best_estimate <- result$estimate
best_method <- result$estimator
# 最佳结果对应的各种图像
plot(result, dat_orig = X, estimator = c('thresholdingEst', 'scadEst', 'adaptiveLassoEst'),
plot_type = "summary", stat = c('min'), abs_v = F)Summary plot defaults to the optimal selected estimator.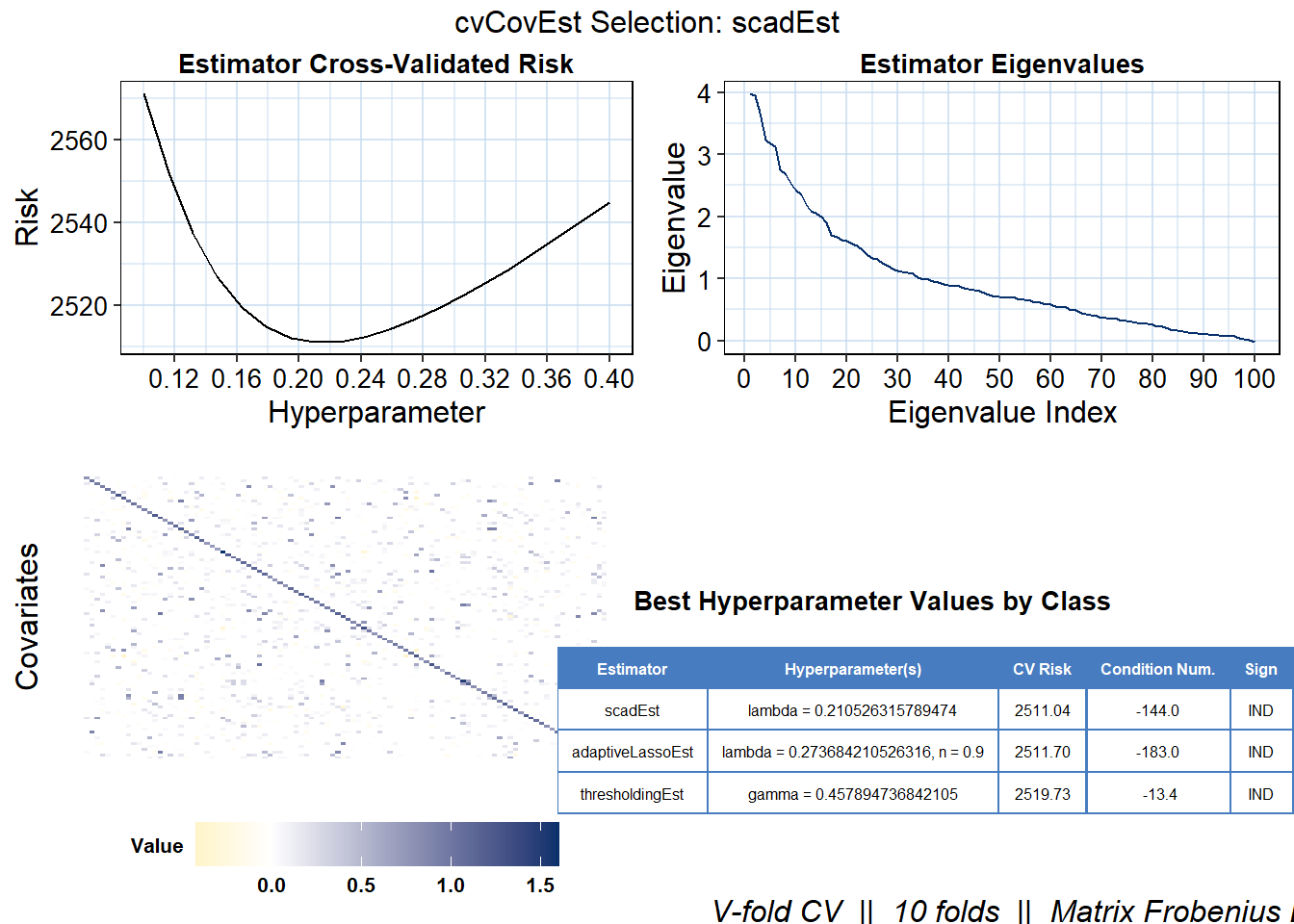
# 数值比较
cat("Best Method:", best_method, "\n")Best Method: scadEst, lambda = 0.210526315789474 cat("Frobenius Norm Error:", norm(true_cov - best_estimate, "F"), "\n")Frobenius Norm Error: 7.322798 # 图形比较
par(mfrow = c(1, 2))
image(Matrix(true_cov), main = "True Covariance Matrix")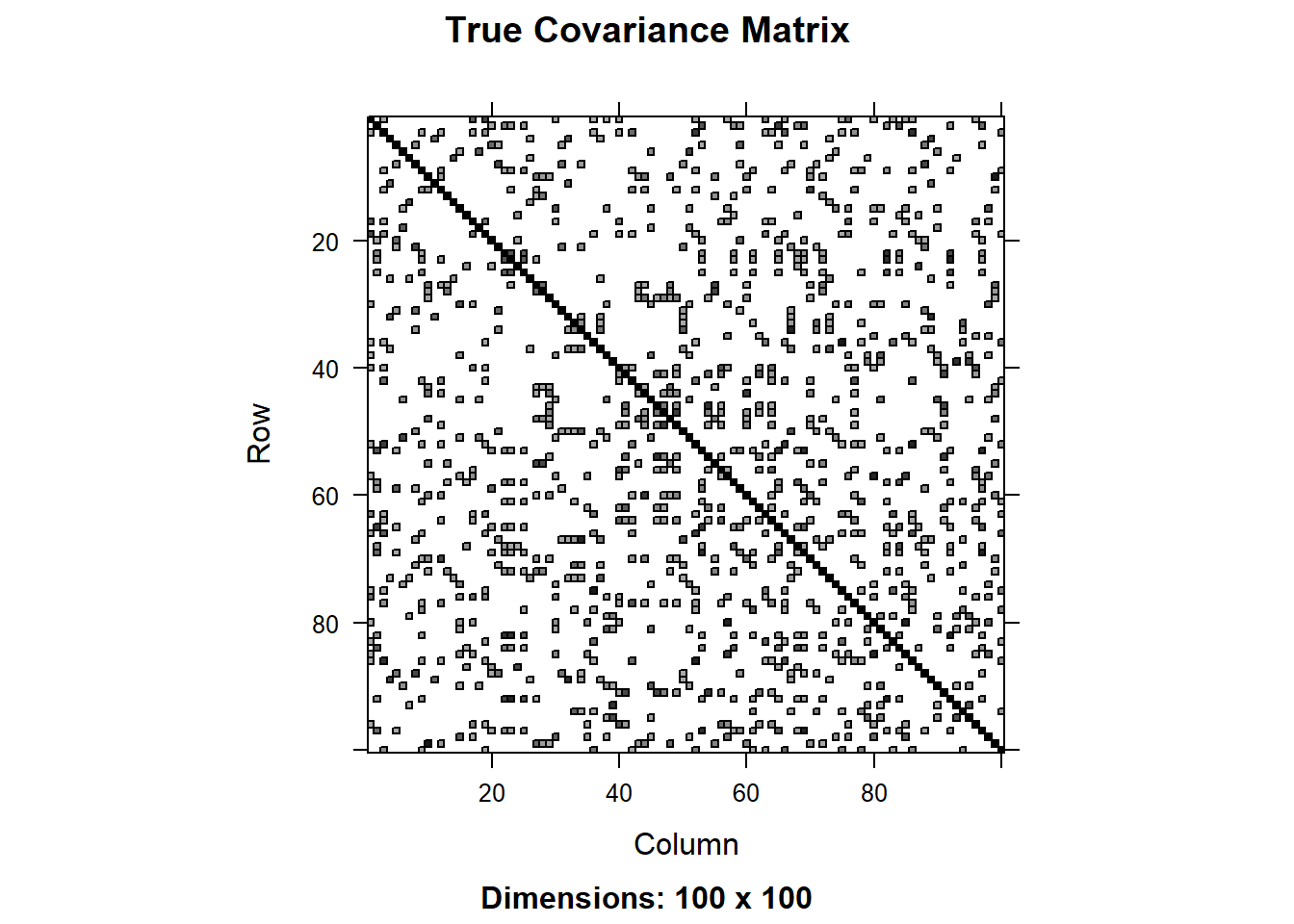
image(Matrix(best_estimate), main = paste("Best Estimate (", best_method, ")", sep = ""))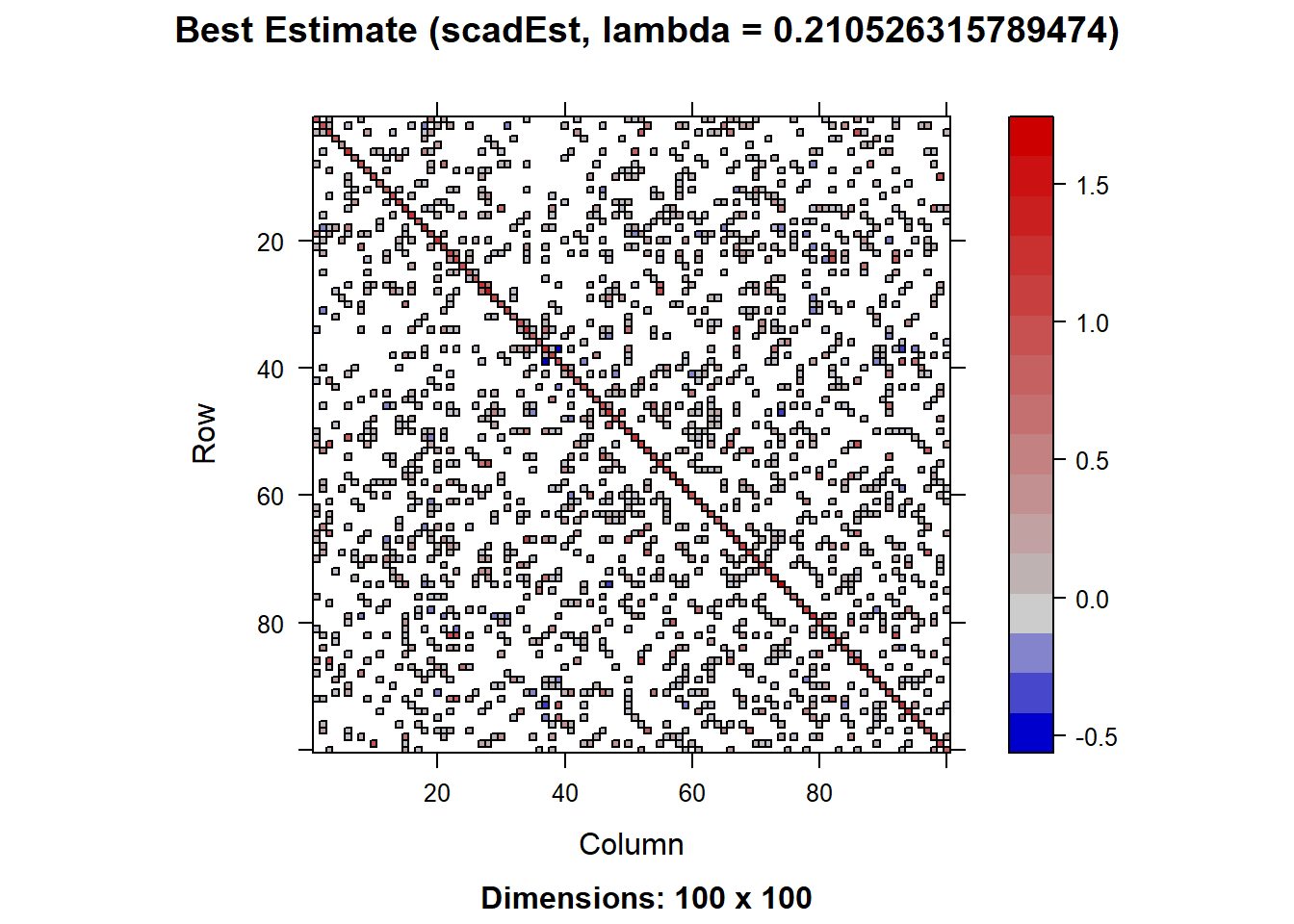
3 无稀疏结构下的压缩估计
前述的高维协方差矩阵估计方法均建立在总体协方差矩阵具有稀疏结构的假设之上,尽管该假设条件在一些应用中是合理的,但是并不总是适用的。比如,对股票市场中的收益率变量来说,由于所有股票收到同样的市场风险影响,股票收益率两两之间总是相关的,此时稀疏性假设就不适用了。在系数结构假设不成立的情况下,应当如何估计高维协方差矩阵?压缩估计是其中一种方法。
3.1 线性压缩估计
Ledoit and Wolf (2004)提出了线性压缩(Linear Shrinkage)方法,通过对样本协方差矩阵向一个目标矩阵\(T\)收缩,从而提高估计的稳定性和精度。为了引出该估计量,我们首先将目标矩阵确定为单位矩阵\(I_p\),通过线性组合样本协方差矩阵\(S\)和目标矩阵\(I_p\),生成收缩后的协方差矩阵: \[ \hat{\Sigma}^{\text{shrink}} = \rho_1 S + \rho_2 I_p \tag{8}\] 其中,\(\rho_1\)和\(\rho_2\)是收缩系数,控制样本协方差矩阵和目标矩阵的权重。我们下一步通过最小化均方误差来确定最优收缩系数,即 \[ \min_{\rho_1,\rho_2} \mathbb{E}\left[ \|\hat{\Sigma}^{\text{shrink}} - \Sigma\|_F^2 \right] \] 其中,\(\Sigma\)是真实的协方差矩阵。Ledoit and Wolf (2004)给出了最优收缩系数表达式为: \[ \rho_1=\frac{\alpha^2}{\delta^2},\quad \quad \rho_2=\frac{\beta^2}{\delta^2}\mu \] 其中\(m = \langle \Sigma,I_p \rangle=\mathrm{tr}(\Sigma I_p)/p\),\(\alpha^2=\|\Sigma-m I_p\|_F^2\), \(\beta^2=E\left[\|S-\Sigma\|_F^2\right]\),以及\(\delta^2=E\left[\|S-m I_p\|_F^2 \right]\)。具体来说,\(m\)是总体协方差矩阵对角线元素的平均值,即\(\mathbf X\)中各变量方差的平均值,剩余3个量满足关系式\(\alpha^2+\beta^2=\delta^2\)。基于此,我们令\(\rho = \frac{\alpha^2}{\delta^2}\),那么 式 8 此时可以表示为 \[ \hat{\Sigma}^{\text{shrink}} = \rho S + (1-\rho) T \tag{9}\] 其中目标矩阵变为\(T=m I_p\),参数\(m\)可以由数据中各变量样本方差的平均值估计,即\(\hat m = \frac{1}{p}\sum_{i=1}^p S_{ii}\)。参数\(\rho\)可以有两种方法进行选择:交叉验证和插值法。使用插值法时需要基于样本数据估计出\(\beta^2\)和\(\delta^2\),一种估计方式是\(\hat \delta^2 = \|S-\hat m I_p\|_F^2\)以及 \[ \hat \beta^2 = \frac{1}{n}\sum_{t=1}^n \|(\mathbf X_t-\bar{\mathbf X})(\mathbf X_t-\bar{\mathbf X})^T - S \|_F^2, \] 那么\(\hat \rho = 1-\hat \beta^2/\hat \delta^2\)。
线性压缩估计量 式 9 本质上是将样本协方差矩阵的特征值向\(m\)进行线性压缩。设\(\lambda_1\ge \lambda_2\ge \dots \ge \lambda_p\)为样本协方差矩阵\(S\)的特征值,\(U\)是对应的特征向量矩阵,那么有\(S=U \Lambda U^T\),其中\(\Lambda\)是对角线元素为\(\lambda_1,\cdots,\lambda_p\)的对角矩阵。根据\(I_p = UU^T\),那么 式 9 可以写作 \[ \hat{\Sigma}^{\text{shrink}} = U\left[\rho\Lambda+(1-\rho)mI_p \right]U^T, \] 其中,经线性压缩调整后的特征值写作\(\rho \lambda_i+(1-\rho)m\)。在高维情形下,样本协方差矩阵的特征值分布会偏离总体协方差矩阵特征值的分布,表现在样本协方差矩阵特征值的分布会更加分散,即严重高估最大特征的同时也会大大低估最小特征值。为解决这一问题,线性压缩估计量将样本协方差特征值向\(m\)收缩靠拢,从而获得更为稳健的估计。
3.2 非线性压缩估计
Ledoit and Wolf (2020)进一步将线性压缩拓展到非线性收缩(Nonlinear Shrinkage)方法。与线性收缩方法不同,非线性收缩方法通过非线性变换\(\delta(\cdot)\)对样本协方差矩阵的特征值进行调整。具体过程如下:第一步,对样本协方差矩阵进行特征值分解\(S = U \Lambda U^T\),其中,\(U\)是特征向量矩阵,\(\Lambda\)是对角矩阵,包含样本协方差矩阵的特征值\(\lambda_1, \lambda_2, \dots, \lambda_p\);第二步,对样本协方差矩阵的特征值\(\lambda_i,i=1,\cdots,p\)进行非线性调整,生成收缩后的特征值\(\delta_i = \delta(\lambda_i)\)以及响应的对角矩阵\(\Delta\),那么非线性压缩估计量可以表示为 \[ \hat{\Sigma}^{\text{nl-shrink}} = U\Delta U^T. \tag{10}\]
接下来的问题是:非线性变换\(\delta(\cdot)\)应使用什么样的形式?Ledoit and Wolf (2020)给出了如下变换: \[ \delta(x) = \frac{x}{[\pi c x f(x)]^2+[1-c-\pi cx\mathcal H_f(x)]^2}, \tag{11}\] 其中,常数\(c=\lim_{n \to \infty} p/n\),注意高维下我们一般假设\(p \to \infty\)随着\(n \to \infty\),函数\(f\)可以粗略地理解为总体协方差矩阵特征值分布的密度函数,\(\mathcal H_f\)是函数\(f\)的希尔伯特变换(Hilbert Transform): \[ \mathcal H_f(x) = \frac{1}{\pi}\mathrm{PV} \int_{-\infty}^\infty f(t)\frac{dt}{t-x}. \] 上式中,PV是指柯西主值(Principal Value),由于积分函数在\(t=x\)处存在无穷点,柯西主值 \[ \mathrm{PV} \int_{-\infty}^\infty f(t)\frac{dt}{t-x} \equiv \lim_{\varepsilon \to 0^+}\left[ \int_{-\infty}^{x-\varepsilon}f(t)\frac{dt}{t-x}+ \int_{x+\varepsilon}^\infty f(t)\frac{dt}{t-x}\right] \] 可以更严格地处理这个奇异积分。希尔伯特变换的作用类似于一种局部调整机制,根据函数在附近点的值对当前位置的值进行增强或减弱:当附近有较大的函数值时,希尔伯特变换会将函数值向上调整;当附近有较小的函数值时,希尔伯特变换会将函数值向下调整,类似于“削峰填谷”,达到“收缩”的效果。
非线性变换 式 11 中包含两个未知的量:常数\(c\)和密度函数\(f\)。其中常数\(c\)可以简单地使用\(\hat c = p/n\)进行估计。对于密度函数\(f\),Ledoit and Wolf (2020)使用\(\lambda_1,\lambda_2,\cdots,\lambda_p\)作为“样本点”,并结合变带宽核密度估计量进行估计: \[ \hat f(x) = \frac{1}{p \lambda_i h}\sum_{i=1}^p K\left(\frac{x-\lambda_i}{\lambda_i h} \right), \] 其中固定带宽\(h \to 0\)需要在估计前进行选择,Ledoit and Wolf (2020)建议将其设置为\(h=n^{-1/3}\),\(K(\cdot)\)为核函数。由于希尔伯特变换是线性算子,该估计量对应的希尔伯特变换写作 \[ \mathcal H_{\hat f} = \frac{1}{p \lambda_i h}\sum_{i=1}^p \mathcal H_K\left(\frac{x-\lambda_i}{\lambda_i h} \right). \] 如果使用常用的Epanechnikov核函数\(K(x) = \frac{3}{4\sqrt{5}}(1-x^2/5)_+\),对应的希尔伯特变换写作 \[ \mathcal H_K(x)=\begin{cases} -\frac{3x}{10\pi}+\frac{3}{4\sqrt{5}\pi}\left(1-\frac{x^2}{5}\right)\log\left| \frac{\sqrt{5}-x}{\sqrt{5}+x} \right| \quad &|x|\ne \sqrt{5}\\ -\frac{3x}{10\pi} \quad & |x|=\sqrt{5}. \end{cases} \]
4 因子结构假设与高维协方差矩阵估计方法
在稀疏性结构假设不适用的应用中,除了压缩估计之外,另外一种技术路线是假设高维数据可以由少量的共同因子解释,这一假设在金融数据分析中通常是合理的,其本质是对高维协方差矩阵做了一定程度的低秩结构假设。
假设数据具有线性因子结构: \[ X_{it} = \mu_i + \mathbf b_i^T \cdot \mathbf f_t + u_{it}, \tag{12}\] 其中\(\mu_i\)是第\(i\)个变量\(X_i\)的均值,\(\mathbf f_t\)是\(K\)个共同因子组成的向量,\(\mathbf b_i\)则是第\(i\)个变量对应的因子载荷向量,\(u_{it}\)是误差项,也称异质性成分,通常假设与因子\(\mathbf f_t\)不相关。这一因子结构 式 12 的矩阵形式写作: \[ \mathbf X_t = \boldsymbol \mu + \mathbf B \mathbf f_t + \mathbf u_t \tag{13}\] 其中\(\mathbf X_t = (X_{1t},\cdots,X_{pt})^T\),\(\mathbf u_t = (u_{1t},\cdots,u_{pt})^T\),以及\(p\times K\)的因子载荷矩阵\(\mathbf B = (\mathbf b_1,\cdots,\mathbf b_p)^T\)。在因子结构 式 13 下,\(\mathbf X_t\)的总体协方差矩阵可以表示为 \[ \Sigma = \mathbf B \Sigma_f \mathbf B^T +\Sigma_u \tag{14}\] 其中\(\Sigma_f = \mathrm{Cov}\{\mathbf f_t\}\) 为共同因子的协方差矩阵,\(\Sigma_u\)为\(\mathbf u_t\)的协方差矩阵。在因子模型中,我们往往需要对异质项的协方差\(\Sigma_u\)做一定的结构假设。Fan et al (2008) 假设\(\Sigma_u\)为对角矩阵,在\(p\to \infty\)且\(p\)可能大于\(n\)的情形下研究了基于 式 14 估计高维协方差矩阵。近似因子模型(approximate factor model)假设给定共同因子下\(\mathbf X_t\)间仍然可能存在弱相关性,即\(\Sigma_u\)为非对角矩阵,在非对角线区域存在许多较小的非零元素。对于高维协方差矩阵估计而言,一个介于中间且更为合理的假设是\(\Sigma_u\)虽然不是对角矩阵,但是具有稀疏结构。
4.1 可观测因子
假设 式 12 中的因子可观测。这一假设在一些应用中是合理的,比如著名的Fama-French三因子/五因子模型。那么高维协方差矩阵\(\Sigma\)可以很方便地根据 式 14 并结合\(\Sigma_u\)的稀疏假设进行估计。
第一步,将数据中的\(p\)个变量逐次对共同因子做普通最小二乘回归,即对于\(i=1,\cdots,p\),得到估计\(\hat \mu_i\)和\(\hat{\mathbf b}_i\)如下: \[ (\hat \mu_i, \hat{\mathbf b}_i) = \arg\min_{\mu_i, \mathbf b_i} \frac{1}{n}\sum_{t=1}^n (X_{it}-\mu_i - \mathbf b_i^T \mathbf f_t)^2. \] 由此可得载荷矩阵估计\(\hat{\mathbf B} = (\hat{\mathbf b}_1,\cdots,\hat{\mathbf b}_p)^T\)和样本残差\(\hat u_{it} = X_{it} - \hat \mu_i -\hat{\mathbf b}_i^T \mathbf f_t\)。记\(\hat{\mathbf u}_t = (\hat u_{1t},\cdots,\hat u_{pt})^T\),那么残差协方差矩阵可表示为 \[ S_u = \frac{1}{n}\sum_{t=1}^n \hat{\mathbf u}_t\hat{\mathbf u}_t^T. \]
第二步,在\(\Sigma_u\)为稀疏结构的假设前提下,使用阈值法对\(S_u\)做修正,得到估计\(\hat \Sigma_u\),即 \[ \hat \Sigma_{u,ij} = \begin{cases} S_{u,ij}, \quad & i=j;\\ h(S_{u,ij};\omega), \quad & i\ne j. \end{cases} \] 其中压缩函数\(h(\cdot;\omega)\)可以使用前述任一适合的形式,比如硬阈值、软阈值、SCAD或者MCP,也可以是硬阈值或者软阈值的自适应改进,阈值参数\(\omega=C\cdot K \sqrt{\frac{\log p}{n}}\),常数\(C>0\)可以由交叉验证进行选择。
第三步,计算因子数据的样本协方差矩阵,即 \[ S_f = \frac{1}{n}\sum_{t=1}^n (\mathbf f_t-\bar{\mathbf f})(\mathbf f_t-\bar{\mathbf f})^T, \quad \quad \bar{\mathbf f} = \frac{1}{n}\sum_{t=1}^n \mathbf f_t. \] 由于共同因子数量\(K\)较小,此时样本协方差矩阵\(S_f\)无需进行调整。最终,我们得到高维协方差矩阵估计量为 \[ \hat \Sigma^{\text{observed-factor}} = \hat{\mathbf B}S_f\hat{\mathbf B}^T+\hat \Sigma_u. \]
4.2 潜因子
在许多应用中,共同因子的研究面临两大挑战:其一,现有理论难以准确识别哪些因素构成共同因子;其二,即使共同因子的形式已知,它们也可能无法直接观测。这类无法直接观测的因子被称为潜因子。
在潜因子的假设下,因子结构 式 13 中的载荷矩阵\(\mathbf B\)和因子\(\mathbf f_t\)无法同时识别。这是因为对于任意一个\(K\times K\)非奇异矩阵\(\mathbf H\),\((\mathbf B,\mathbf f_t)\)和\((\mathbf B \mathbf H^{-1},\mathbf H \mathbf f_t)\)是等价的。矩阵\(\mathbf H\)通常被称为旋转矩阵。这一现象表明,因子(或因子载荷)的识别具有旋转不确定性,或者说因子只能在旋转矩阵的意义下被识别。因此,我们需要引入一些额外的假设条件来保证模型的可识别性。在高维协方差矩阵估计中,Fan, Liao and Mincheva (2013)提出了以下两个识别条件:(1) 共同因子的协方差矩阵为单位阵,即\(\Sigma_f = I_K\); (2) 载荷矩阵\(\mathbf B\)的列向量正交,即\(\mathbf B^T \mathbf B\)为\(K\times K\)对角矩阵。在这两个条件下,式 14 中协方差矩阵\(\Sigma\)的分解可以简化为 \[ \Sigma = \mathbf B \mathbf B^T + \Sigma_u. \]
接下来的关键问题是如何将低秩部分\(\mathbf B \mathbf B^T\)与异质性部分\(\Sigma_u\)进行分离。当\(\Sigma_u\)为非对角阵时,在\((p,n)\)有限的情况下,两者的分离是无法完成的。然而,Fan, Liao and Mincheva (2013)指出,当变量数量\(p \to \infty\)时,这一分离是可行的。此外,还需要满足以下条件:1)矩阵\(\Sigma_u\)的特征值一致有界,或者随着\(p\to \infty\)缓慢增长;2)因子为全局因子(pervasive factor),即\(K\)个共同因子对几乎所有的\(p\)个变量都有影响。这一条件的数学表述为:随着\(p\to \infty\),\(K\times K\)矩阵\(p^{-1}\mathbf B^T \mathbf B\)的特征值一致有界且远离0。在这些假设条件下,Fan, Liao and Mincheva (2013)得出了以下结论:记矩阵\(\Sigma\)的特征值为\(\lambda_1^* \ge \lambda_2^* \ge \cdots \ge \lambda_p^*\),特征值\(\lambda_i^*\)对应的特征向量为\(\xi_i^*\),那么 \[ \mathbf B \mathbf B^T \approx \sum_{i=1}^K \lambda_i^* \xi_i^* \xi_i^{*T}, \tag{15}\] 同时,根据特征分解\(\Sigma = \sum_{i=1}^p \lambda_i^* \xi_i^* \xi_i^{*T}\)以及因子分解\(\Sigma = \mathbf B \mathbf B^T + \Sigma_u\),可以进一步得到 \[ \Sigma_u \approx \sum_{i=K+1}^p \lambda_i^* \xi_i^* \xi_i^{*T}. \tag{16}\]
在 式 15 和 式 16 的基础上,Fan, Liao and Mincheva (2013)提出了POET(Principal Orthogonal complEment Thresholding)估计量。首先,将样本协方差矩阵\(S\)进行特征分解,得到特征值\(\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_p\)和对应的特征向量\(\xi_1,\xi_2,\cdots,\xi_p\),那么样本协方差矩阵可以表示为 \[ S=\sum_{i=1}^K \lambda_i \xi_i \xi_i^{T}+S_u, \] 其中\(S_u = \sum_{i=K+1}^p \lambda_i \xi_i \xi_i^{T}\)。接下来,对矩阵\(S_u\)进行广义阈值处理,得到 \[ \hat \Sigma_{u,ij} = \begin{cases} S_{u,ij}, \quad & i=j;\\ h(S_{u,ij};\tilde \omega), \quad & i\ne j. \end{cases} \] 这里可以使用任意适合的压缩函数\(h(\cdot;\tilde \omega)\),其中阈值参数\(\tilde \omega = C\left(\sqrt{\frac{\log p}{n}}+\frac{1}{\sqrt{p}} \right)\),常数\(C>0\)可以通过交叉验证进行选择。与可观测因子下的阈值参数\(\omega\)相比,潜因子下的阈值参数\(\tilde \omega\)多了一项\(1/\sqrt{p}\),这一项可以理解为因子未知所付出的代价。当变量个数\(p\)远大于样本容量\(n\)时,这一项可以忽略不计。最终,POET估计量的形式为 \[ \hat \Sigma^{\text{POET}} = \sum_{i=1}^K \lambda_i \xi_i \xi_i^{T} + \hat \Sigma_u. \]
值得注意的是,POET估计量依赖于共同因子的个数\(K\),然而这一信息在现实中通常是未知的。文献中有许多估计因子个数\(K\)的方法,例如Bai and Ng (2002)的信息准则法。理论上,任何一致的方法都可以使用。Fan, Liao and Mincheva (2013)的仿真模拟结果表明,POET估计量在因子个数被高估的情况下依然是稳健的,因此在实践中,我们可以选择相对较大的\(K\)值。
# 安装和加载所需包
library(pedquant)Warning: package 'pedquant' was built under R version 4.4.3library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ lubridate 1.9.2 ✔ tibble 3.2.1
✔ purrr 1.0.1 ✔ tidyr 1.3.0
✔ readr 2.1.4
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ purrr::%||%() masks base::%||%()
✖ tidyr::expand() masks Matrix::expand()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ tidyr::pack() masks Matrix::pack()
✖ dplyr::select() masks MASS::select()
✖ tidyr::unpack() masks Matrix::unpack()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(quantmod)Loading required package: xts
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
######################### Warning from 'xts' package ##########################
# #
# The dplyr lag() function breaks how base R's lag() function is supposed to #
# work, which breaks lag(my_xts). Calls to lag(my_xts) that you type or #
# source() into this session won't work correctly. #
# #
# Use stats::lag() to make sure you're not using dplyr::lag(), or you can add #
# conflictRules('dplyr', exclude = 'lag') to your .Rprofile to stop #
# dplyr from breaking base R's lag() function. #
# #
# Code in packages is not affected. It's protected by R's namespace mechanism #
# Set `options(xts.warn_dplyr_breaks_lag = FALSE)` to suppress this warning. #
# #
###############################################################################
Attaching package: 'xts'
The following objects are masked from 'package:dplyr':
first, last
Loading required package: TTR
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo library(cvCovEst)
library(POET)
library(Matrix)
# 沪深300成分股股票代码向量
hs300_stock_codes <- c(
"600000.SH", "600004.SH", "600009.SH", "600010.SH", "600011.SH", "600015.SH",
"600016.SH", "600018.SH", "600019.SH", "600025.SH", "600028.SH", "600029.SH",
"600030.SH", "600031.SH", "600036.SH", "600048.SH", "600050.SH", "600104.SH",
"600109.SH", "600111.SH", "600115.SH", "600118.SH", "600170.SH", "600176.SH",
"600177.SH", "600183.SH", "600188.SH", "600196.SH", "600208.SH", "600219.SH",
"600221.SH", "600233.SH", "600271.SH", "600276.SH", "600297.SH", "600309.SH",
"600332.SH", "600340.SH", "600346.SH", "600352.SH", "600362.SH", "600369.SH",
"600383.SH", "600390.SH", "600406.SH", "600436.SH", "600438.SH", "600482.SH",
"600487.SH", "600489.SH", "600498.SH", "600516.SH", "600519.SH", "600522.SH",
"600547.SH", "600570.SH", "600585.SH", "600588.SH", "600606.SH", "600637.SH",
"600655.SH", "600660.SH", "600663.SH", "600674.SH", "600690.SH", "600703.SH",
"600705.SH", "600741.SH", "600745.SH", "600760.SH", "600795.SH", "600809.SH",
"600837.SH", "600848.SH", "600867.SH", "600886.SH", "600887.SH", "600893.SH",
"600900.SH", "600905.SH", "600919.SH", "600926.SH", "600928.SH", "600929.SH",
"600933.SH", "600938.SH", "600958.SH", "600959.SH", "600968.SH", "600977.SH",
"600989.SH", "600998.SH", "600999.SH", "601006.SH", "601009.SH", "601012.SH",
"601018.SH", "601021.SH", "601066.SH", "601077.SH", "601088.SH", "601099.SH",
"601100.SH", "601108.SH", "601111.SH", "601117.SH", "601138.SH", "601155.SH",
"601162.SH", "601166.SH", "601169.SH", "601186.SH", "601198.SH", "601211.SH",
"601216.SH", "601225.SH", "601229.SH", "601231.SH", "601236.SH", "601238.SH",
"601288.SH", "601318.SH", "601319.SH", "601328.SH", "601336.SH", "601360.SH",
"601377.SH", "601390.SH", "601398.SH", "601555.SH", "601577.SH", "601600.SH",
"601601.SH", "601607.SH", "601618.SH", "601628.SH", "601633.SH", "601658.SH",
"601668.SH", "601669.SH", "601688.SH", "601696.SH", "601698.SH", "601727.SH",
"601766.SH", "601788.SH", "601800.SH", "601808.SH", "601818.SH", "601828.SH",
"601838.SH", "601857.SH", "601878.SH", "601881.SH", "601888.SH", "601898.SH",
"601899.SH", "601901.SH", "601916.SH", "601919.SH", "601933.SH", "601939.SH",
"601985.SH", "601988.SH", "601989.SH", "601992.SH", "601997.SH", "601998.SH",
"603019.SH", "603156.SH", "603160.SH", "603259.SH", "603288.SH", "603369.SH",
"603501.SH", "603658.SH", "603799.SH", "603833.SH", "603899.SH", "603986.SH",
"603993.SH", "688008.SH", "688009.SH", "688012.SH", "688036.SH", "688111.SH",
"688126.SH", "688169.SH", "688396.SH", "688561.SH", "000001.SZ", "000002.SZ",
"000063.SZ", "000066.SZ", "000069.SZ", "000100.SZ", "000157.SZ", "000166.SZ",
"000333.SZ", "000338.SZ", "000425.SZ", "000538.SZ", "000568.SZ", "000596.SZ",
"000625.SZ", "000627.SZ", "000651.SZ", "000656.SZ", "000661.SZ", "000671.SZ",
"000703.SZ", "000708.SZ", "000709.SZ", "000723.SZ", "000725.SZ", "000728.SZ",
"000738.SZ", "000768.SZ", "000776.SZ", "000783.SZ", "000786.SZ", "000858.SZ",
"000860.SZ", "000876.SZ", "000895.SZ", "000938.SZ", "000959.SZ", "000961.SZ",
"000963.SZ", "000977.SZ", "001979.SZ", "002001.SZ", "002007.SZ", "002008.SZ",
"002024.SZ", "002027.SZ", "002032.SZ", "002044.SZ", "002049.SZ", "002050.SZ",
"002120.SZ", "002142.SZ", "002146.SZ", "002153.SZ", "002179.SZ", "002202.SZ",
"002230.SZ", "002236.SZ", "002241.SZ", "002252.SZ", "002271.SZ", "002304.SZ",
"002311.SZ", "002352.SZ", "002371.SZ", "002410.SZ", "002415.SZ", "002422.SZ",
"002456.SZ", "002460.SZ", "002466.SZ", "002475.SZ", "002493.SZ", "002555.SZ",
"002594.SZ", "002601.SZ", "002602.SZ", "002607.SZ", "002624.SZ", "002648.SZ",
"002714.SZ", "002736.SZ", "002739.SZ", "002812.SZ", "002821.SZ", "002831.SZ",
"002841.SZ", "002916.SZ", "002938.SZ", "002939.SZ", "002945.SZ", "002958.SZ",
"003816.SZ", "300003.SZ", "300014.SZ", "300015.SZ", "300033.SZ", "300059.SZ",
"300122.SZ", "300124.SZ", "300136.SZ", "300142.SZ", "300144.SZ", "300347.SZ",
"300408.SZ", "300413.SZ", "300433.SZ", "300498.SZ", "300601.SZ", "300628.SZ",
"300661.SZ", "300676.SZ", "300750.SZ", "300759.SZ", "300760.SZ", "300782.SZ",
"300832.SZ", "300866.SZ", "300896.SZ"
)
# 从沪深300成分股中随机抽取100支股票
# 设置种子以保证可重复性
set.seed(1037)
symbol <- sample(hs300_stock_codes, size = 100, replace = F)
# 获取股票数据,md_stock函数默认返回列表,列表中的元素为单支股票的数据
dat <- md_stock(symbol, date_range = '3y', source = "163", print_step = 0)
# 定义一个函数,将数据框格式转换为xts对象,然后返回相应的收益率数据
calculate_returns <- function(df,
date_col = "date",
price_col = "close",
period = c("daily", "weekly", "monthly", "quarterly", "yearly")) {
# 转换日期格式
df[[date_col]] <- as.Date(df[[date_col]])
# 创建xts对象
price_xts <- xts(df[[price_col]], order.by = df[[date_col]])
colnames(price_xts) <- price_col
# 计算收益率
returns <- periodReturn(price_xts, period = period, type = "arithmetic")
# 重命名列
colnames(returns) <- paste0(period, "_return")
return(returns)
}
# 计算每支股票的周度收益率
weekly_return <- lapply(dat, calculate_returns, period = 'weekly')
# 将列表中不同股票的收益率数据按照日期进行合并
weekly_return <- reduce(weekly_return, .f = merge.xts, join = 'inner')
# 将weekly_return 中的列名设置为对应的股票代码
colnames(weekly_return) <- symbol
# 查看数据并绘制收益率曲线
head(weekly_return) 000768.SZ 600837.SH 688111.SH 603501.SH 601555.SH
2022-03-18 0.0006896552 0.002854424 0.010257745 0.07826923 0.009421265
2022-03-25 -0.0017229497 -0.028462998 -0.029172250 -0.08507223 -0.029333333
2022-04-15 -0.0419069589 -0.012770138 0.006493146 -0.03496115 -0.014569536
2022-04-22 -0.0489566613 -0.038805970 -0.057123952 -0.14318574 -0.048387097
2022-04-29 -0.0814345992 -0.063146998 0.103508772 0.01006711 -0.040960452
2022-05-06 0.0509875976 -0.033149171 0.049284579 -0.06870432 -0.067746686
002831.SZ 601088.SH 600606.SH 600016.SH 688126.SH
2022-03-18 0.01592852 -0.04465649 0.030150754 -0.002673797 0.058895706
2022-03-25 -0.02485660 0.08589692 0.192682927 0.021447721 -0.106991116
2022-04-15 -0.03252351 0.01504743 -0.064013841 -0.007772021 -0.004424779
2022-04-22 0.05103281 -0.04318402 -0.121996303 -0.023498695 -0.026666667
2022-04-29 -0.04855491 0.03671270 0.008421053 -0.010695187 -0.045662100
2022-05-06 0.06520859 -0.01754386 -0.098121086 -0.021621622 0.011483254
600637.SH 601117.SH 600276.SH 000895.SZ 002410.SZ
2022-03-18 0.01026958 0.038283063 0.002673797 -0.07234957 0.037273695
2022-03-25 -0.02414231 0.051396648 -0.030133333 0.02355212 0.001232033
2022-04-15 -0.01808786 0.000000000 0.004715591 0.10607143 -0.033904987
2022-04-22 -0.03552632 -0.105731225 -0.031974186 0.01679044 -0.045704958
2022-04-29 -0.04774898 0.008839779 -0.106666667 -0.05525564 -0.017104982
2022-05-06 -0.02435530 -0.050383352 -0.004748982 0.02957983 0.054165760
601989.SH 600519.SH 000625.SZ 601601.SH 002202.SZ
2022-03-18 -0.00257732 0.004582353 0.008849558 0.001273345 -0.0150753769
2022-03-25 -0.01033592 -0.010416972 -0.018421053 -0.019499788 -0.0204081633
2022-04-15 0.01038961 0.012326233 -0.054595086 -0.020931226 -0.0822444274
2022-04-22 -0.01542416 -0.018266989 -0.005774783 -0.030541012 -0.0536013400
2022-04-29 -0.06788512 0.031235195 0.013552759 -0.063906391 -0.0008849558
2022-05-06 -0.02240896 -0.019350463 0.125119389 -0.035576923 -0.0203720106
601328.SH 603369.SH 002466.SZ 600332.SH 002044.SZ
2022-03-18 0.020876827 -0.012021371 0.01285628 0.031691354 -0.03721683
2022-03-25 0.004089980 -0.045290671 0.03544486 0.016026711 -0.02016807
2022-04-15 -0.003868472 0.060188542 -0.06631673 -0.018211921 -0.03389831
2022-04-22 0.005825243 0.007979936 -0.08816674 -0.046205734 -0.03333333
2022-04-29 -0.019305019 0.015154942 0.14932331 0.026520509 -0.09255898
2022-05-06 -0.039370079 -0.028520499 0.02656025 0.007578367 -0.00400000
000157.SZ 601828.SH 600905.SH 600369.SH 601985.SH
2022-03-18 -0.008836524 -0.001269036 -0.007621951 0.009153318 0.01903553
2022-03-25 -0.020802377 0.007623888 -0.055299539 -0.038548753 -0.07471980
2022-04-15 -0.064425770 -0.058096415 -0.087520259 -0.009111617 -0.05809642
2022-04-22 -0.058383234 -0.177165354 -0.012433393 -0.043678161 -0.00656168
2022-04-29 -0.077901431 -0.204146730 0.046762590 -0.103365385 -0.05812417
2022-05-06 -0.001724138 0.044088176 -0.022336770 -0.053619303 -0.01542777
600018.SH 600919.SH 601108.SH 002142.SZ 000661.SZ
2022-03-18 0.005357143 0.01883830 0.01972158 0.003492433 -0.05170046
2022-03-25 -0.039076377 0.03389831 -0.02389078 0.046983759 -0.03418308
2022-04-15 -0.012759171 0.02581522 -0.05424528 -0.034282833 -0.02291731
2022-04-22 -0.017770598 -0.00794702 -0.03615960 -0.033933699 -0.06694136
2022-04-29 -0.024671053 -0.02136182 -0.07891332 -0.018913807 0.06678443
2022-05-06 0.035413153 -0.06002729 -0.02387640 -0.014045717 -0.02560183
601018.SH 000538.SZ 601688.SH 601628.SH 300661.SZ
2022-03-18 -0.01007557 0.0003736921 0.029696133 0.032358674 -0.014237805
2022-03-25 -0.01526718 0.0093388121 -0.030851777 -0.043806647 0.039185971
2022-04-15 -0.01449275 -0.0264240309 -0.007323569 -0.004804139 -0.095973261
2022-04-22 -0.01715686 -0.0463448982 -0.044265594 -0.015967323 -0.014084507
2022-04-29 -0.02493766 0.0240300712 -0.063157895 -0.039622642 0.000000000
2022-05-06 -0.02046036 -0.2819874148 -0.039700375 -0.013752456 -0.005821429
002624.SZ 600025.SH 601238.SH 300628.SZ 600887.SH
2022-03-18 0.048639736 -0.031198686 0.025846702 0.006290957 0.014492754
2022-03-25 0.006289308 -0.027118644 -0.033014770 -0.000520969 -0.054232804
2022-04-15 0.015163607 -0.003205128 0.006762468 -0.070865140 0.044642857
2022-04-22 0.033018868 0.011254019 -0.025188917 0.040668219 -0.006734007
2022-04-29 0.124048706 -0.023847377 0.054263566 0.020789474 0.003129074
2022-05-06 -0.061611374 -0.026058632 0.004084967 -0.043825728 -0.018195997
002945.SZ 600176.SH 600004.SH 600111.SH 600926.SH
2022-03-18 0.066748316 0.039203085 0.07976490 0.02634850 0.0007272727
2022-03-25 -0.072330654 -0.061224490 -0.05054432 -0.02591426 -0.0094476744
2022-04-15 0.004590164 -0.016564417 0.05250784 -0.08679642 0.0193204530
2022-04-22 0.011096606 -0.072364317 -0.07222636 -0.09331797 -0.0019607843
2022-04-29 -0.105229180 0.057834566 -0.04012841 0.00635324 0.0006548788
2022-05-06 -0.024531025 0.005085823 -0.04682274 -0.04987374 -0.0301047120
601216.SH 000069.SZ 000786.SZ 601898.SH 002304.SZ
2022-03-18 -0.01702128 0.031496063 0.05444646 -0.01396648 -0.01417129
2022-03-25 -0.01948052 -0.013740458 -0.01927711 0.08215297 -0.05333333
2022-04-15 0.04449153 -0.006501951 -0.01258257 0.22564735 0.00729927
2022-04-22 -0.08519270 -0.098167539 -0.08824466 -0.08551308 0.02956522
2022-04-29 -0.03104213 -0.121915820 0.01432565 0.03410341 0.11951014
2022-05-06 -0.05034325 -0.064462810 0.03203583 0.00212766 -0.03086885
600390.SH 000333.SZ 300347.SZ 600362.SH 600050.SH
2022-03-18 0.00000000 0.038983948 0.06572717 -0.013691684 -0.008287293
2022-03-25 -0.01181102 -0.047707980 0.04517085 0.008226221 -0.022284123
2022-04-15 -0.01498127 0.023024594 0.05381614 0.028440833 -0.008426966
2022-04-22 -0.04372624 -0.028644501 -0.09795918 -0.089876543 -0.002832861
2022-04-29 -0.09145129 0.002106372 -0.05766600 -0.043950081 0.000000000
2022-05-06 -0.01531729 0.019442985 -0.08699051 -0.041997730 -0.017045455
600015.SH 000002.SZ 601398.SH 600309.SH 600010.SH
2022-03-18 -0.005586592 0.084524549 -0.008714597 0.009708738 -0.01298701
2022-03-25 0.003745318 -0.002292264 0.015384615 -0.040310651 -0.02631579
2022-04-15 -0.005263158 -0.008841322 -0.010395010 -0.043718934 -0.01754386
2022-04-22 -0.012345679 -0.069953052 0.016806723 -0.057176610 -0.10267857
2022-04-29 -0.026785714 -0.021706209 -0.012396694 -0.024558326 -0.06467662
2022-05-06 -0.034862385 -0.045923633 -0.008368201 0.021194605 -0.04255319
002027.SZ 002008.SZ 600547.SH 000627.SZ 002939.SZ
2022-03-18 0.02755267 -0.053846154 -0.06646972 0.035947712 0.008171604
2022-03-25 -0.04731861 -0.006605691 0.13660338 -0.028391167 -0.048632219
2022-04-15 -0.01174497 -0.055183946 -0.06263499 -0.018633540 0.052200614
2022-04-22 -0.05093379 -0.147492625 -0.06866359 0.003164557 -0.096303502
2022-04-29 0.04293381 -0.038062284 -0.05195448 -0.104100946 -0.109795479
2022-05-06 -0.02058319 -0.020503597 -0.03810021 0.003521127 -0.059250302
600000.SH 600760.SH 600741.SH 600809.SH 300122.SZ
2022-03-18 -0.001264223 -0.02076677 0.04227405 0.02365672 0.16154806
2022-03-25 -0.012658228 0.08392242 -0.02890443 -0.06029015 -0.01755517
2022-04-15 0.004932182 -0.01985762 0.03822314 0.07353535 -0.11398014
2022-04-22 -0.007361963 -0.03096330 -0.05522388 -0.01738803 -0.11864115
2022-04-29 -0.007416564 -0.01577909 0.03212217 0.04182626 -0.07552338
2022-05-06 -0.022415940 0.05811623 0.01020408 -0.06742647 0.01248677
000066.SZ 300866.SZ 601838.SH 600655.SH 002607.SZ
2022-03-18 -0.01235585 -0.005001429 0.06472727 -0.03958333 -0.01672241
2022-03-25 -0.03502919 0.021111590 -0.01502732 0.06616052 -0.06122449
2022-04-15 -0.08940972 -0.044752093 0.05886116 -0.01272016 -0.05594406
2022-04-22 -0.08007626 -0.029322548 -0.01510574 -0.03865213 -0.10185185
2022-04-29 -0.06528497 -0.014930556 0.03006135 -0.07319588 -0.05567010
2022-05-06 0.09423503 -0.020444131 0.02441930 -0.02113459 0.01528384
002493.SZ 600048.SH 000709.SZ 000876.SZ 000166.SZ
2022-03-18 0.045953361 0.03916769 -0.03719008 -0.001971091 0.004576659
2022-03-25 -0.062950820 -0.01236749 0.00000000 0.070441080 -0.025056948
2022-04-15 -0.054177546 0.06095552 0.04669261 -0.003824092 -0.011261261
2022-04-22 -0.048309179 -0.07971014 -0.09665428 -0.027511196 -0.018223235
2022-04-29 -0.005076142 0.01912261 -0.04115226 -0.076973684 -0.051044084
2022-05-06 0.042274052 -0.09547461 -0.03004292 -0.018531718 -0.039119804
600170.SH 601988.SH 688008.SH 601009.SH 600188.SH
2022-03-18 -0.006389776 0.003236246 -0.004676019 0.02121212 0.017109685
2022-03-25 -0.003215434 0.019354839 -0.046040268 0.02670623 0.128867528
2022-04-15 -0.040697674 -0.003039514 -0.002633311 0.02852204 -0.026246719
2022-04-22 -0.066666667 0.006097561 -0.048844884 0.02521008 -0.070889488
2022-04-29 0.051948052 -0.021212121 0.007113116 -0.04918033 0.007542791
2022-05-06 -0.077160494 -0.012383901 0.023255814 -0.02500000 -0.033976389
600011.SH 601618.SH 300759.SZ 300015.SZ 002415.SZ
2022-03-18 0.006361323 -0.017811705 0.02371999 -0.059191056 0.009073988
2022-03-25 -0.107458913 -0.025906736 0.08693605 0.036700454 -0.053262624
2022-04-15 -0.041979010 -0.048346056 0.07863555 0.074984443 0.013451777
2022-04-22 0.090766823 -0.074866310 0.00982024 -0.002894356 0.021788129
2022-04-29 0.047345768 0.008670520 0.03181144 0.042670537 0.041421569
2022-05-06 -0.068493151 -0.005730659 -0.08186901 0.007238307 -0.180983761
002153.SZ 600999.SH 600745.SH 601162.SH 002001.SZ
2022-03-18 0.03396226 -0.004801097 0.015768854 0.04297994 -0.074854450
2022-03-25 -0.06888686 -0.013783598 -0.090444509 -0.05769231 -0.052741984
2022-04-15 -0.05246753 0.008168822 -0.081444386 -0.03361345 -0.071094207
2022-04-22 -0.04331140 -0.037137070 -0.063701578 -0.06086957 -0.085039370
2022-04-29 0.02578797 -0.104488079 0.007968127 -0.07407407 -0.078485370
2022-05-06 -0.01675978 -0.007830854 -0.071298267 -0.04000000 -0.008591707plot(weekly_return$`000768.SZ`) # 以中航西飞 (000768)为例
plot(density(weekly_return$`000768.SZ`, bw = 'nrd')) # 中航西飞 (000768)周收益率的概率密度估计(基于核密度法)
# 使用 cvCovEst 包进行协方差矩阵估计
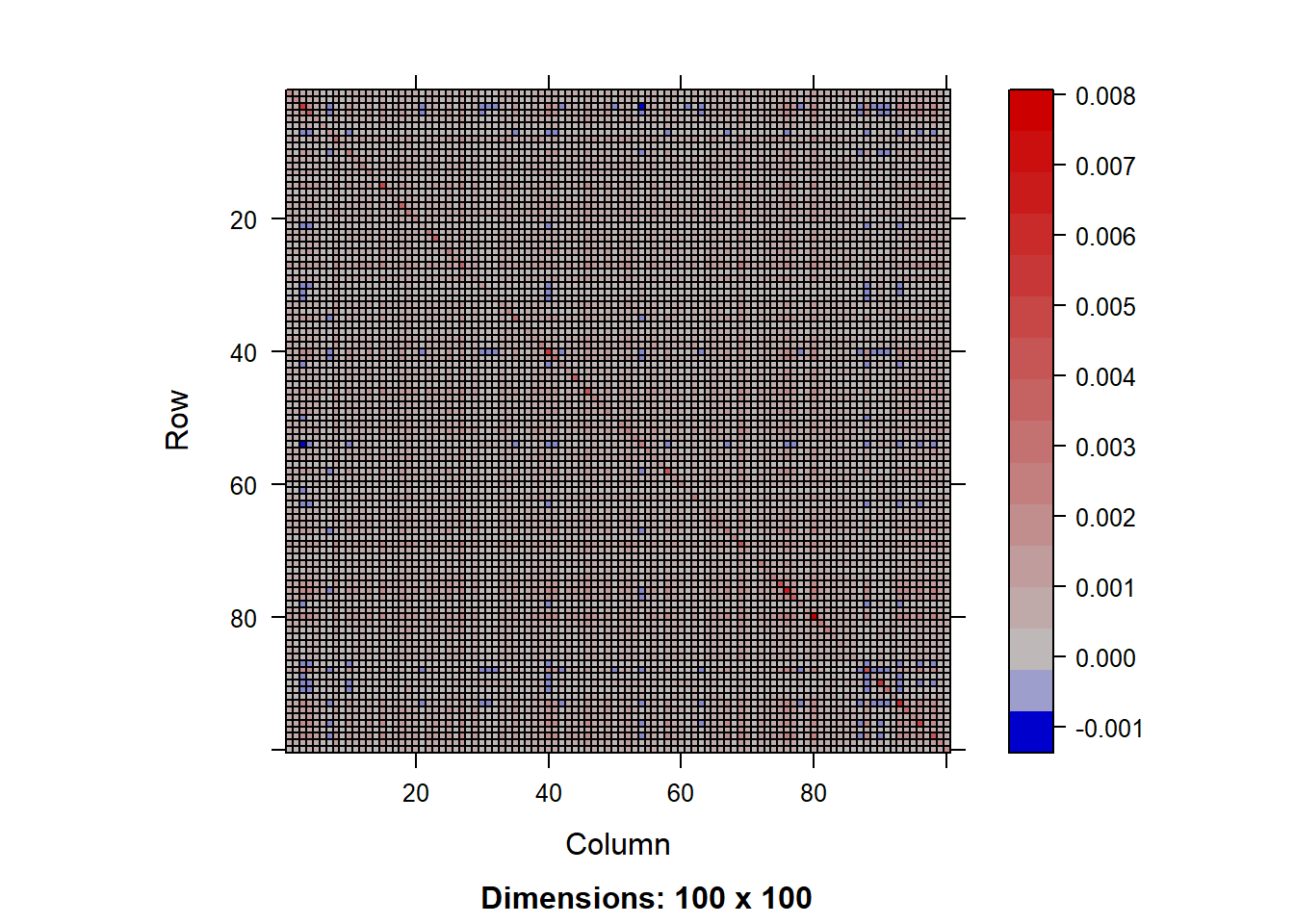
# 线性收缩估计 (Ledoit-Wolf)
linear_shrink_est <- linearShrinkLWEst(dat = as.matrix(weekly_return))
# 非线性收缩估计 (Ledoit-Wolf)
nonlinear_shrink_est <- nlShrinkLWEst(dat = as.matrix(weekly_return))
# POET估计量
# K=-Inf: 共同因子个数由信息准则选取
# C=-Inf: 阈值参数设置为保证估计协方差矩阵正定的最小阈值
poet_est <- POET(Y = t(as.matrix(weekly_return)), K = -Inf, C = -Inf, thres = 'scad', matrix = 'cor')
poet_est <- poet_est$SigmaY
# 报告结果
cat("线性收缩估计的协方差矩阵(前5行5列):\n")线性收缩估计的协方差矩阵(前5行5列):print(linear_shrink_est[1:5, 1:5]) 000768.SZ 600837.SH 688111.SH 603501.SH 601555.SH
000768.SZ 0.0018876299 0.0006178593 0.0005383364 0.0007905771 0.0004937805
600837.SH 0.0006178593 0.0018977439 0.0006161160 0.0006782612 0.0006753979
688111.SH 0.0005383364 0.0006161160 0.0051855951 0.0012686474 0.0004882563
603501.SH 0.0007905771 0.0006782612 0.0012686474 0.0035586107 0.0006648710
601555.SH 0.0004937805 0.0006753979 0.0004882563 0.0006648710 0.0015773044cat("\n非线性收缩估计的协方差矩阵(前5行5列):\n")
非线性收缩估计的协方差矩阵(前5行5列):print(nonlinear_shrink_est[1:5, 1:5]) [,1] [,2] [,3] [,4] [,5]
[1,] 0.0006392510 0.0001050958 0.0001464055 0.0001716904 0.0001483097
[2,] 0.0001050958 0.0006315629 0.0001258757 0.0001151502 0.0001471647
[3,] 0.0001464055 0.0001258757 0.0009760489 0.0003459588 0.0001634412
[4,] 0.0001716904 0.0001151502 0.0003459588 0.0009731397 0.0001718022
[5,] 0.0001483097 0.0001471647 0.0001634412 0.0001718022 0.0007287181cat("\n POET估计的协方差矩阵(前5行5列):\n")
POET估计的协方差矩阵(前5行5列):print(poet_est[1:5, 1:5]) 000768.SZ 600837.SH 688111.SH 603501.SH 601555.SH
000768.SZ 0.0018323192 0.0004358711 0.0006038469 0.0007260704 0.0006170429
600837.SH 0.0004358711 0.0018436861 0.0004407027 0.0005827351 0.0005770025
688111.SH 0.0006038469 0.0004407027 0.0055388526 0.0017015466 0.0005961121
603501.SH 0.0007260704 0.0005827351 0.0017015466 0.0037103094 0.0008052621
601555.SH 0.0006170429 0.0005770025 0.0005961121 0.0008052621 0.0014835490# 可视化协方差矩阵
image(Matrix(linear_shrink_est), title = "线性收缩估计的相关矩阵")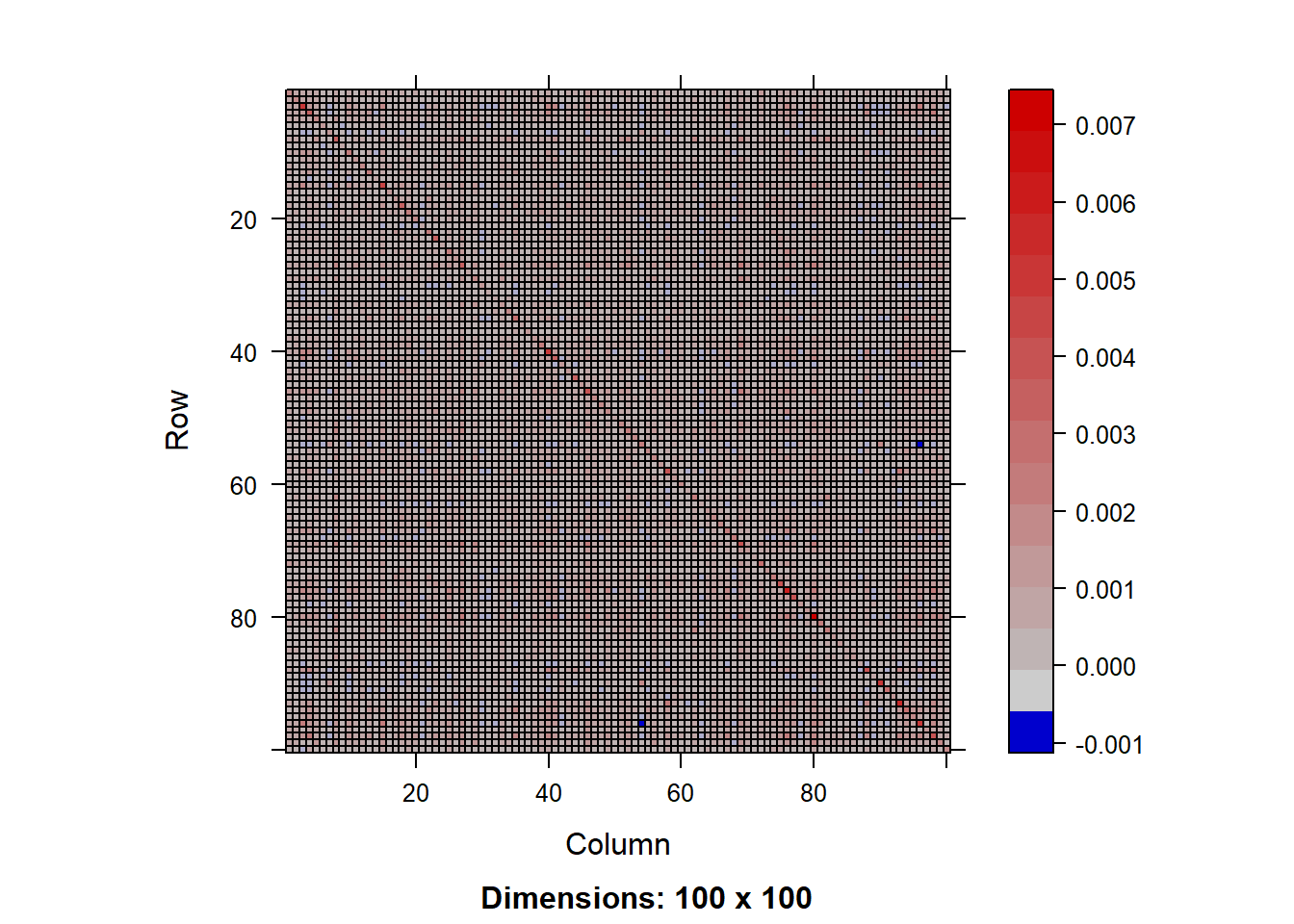
image(Matrix(nonlinear_shrink_est), title = "非线性收缩估计的相关矩阵")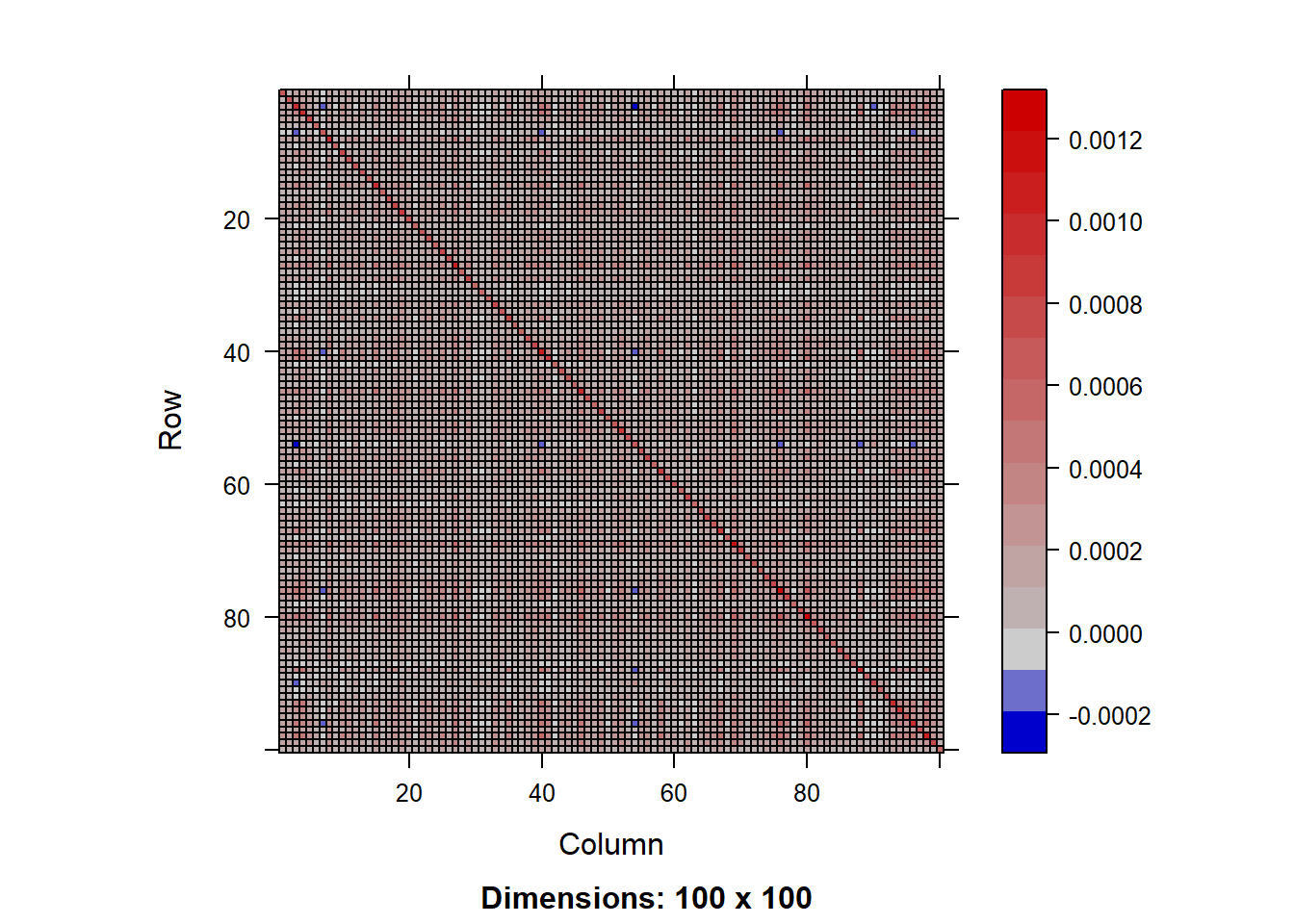
image(Matrix(poet_est), title = "POET估计的相关矩阵")